So You Want To Put Blackboard Data In A Learning Record Store
by Cameron Finn Kelly
Preamble
You're a developer in the unenviable position of delivering live learning data to researchers whose students use Blackboard. They don't know about database tables or cron jobs; they just know that their students are doing things online, they want to know the who, what, where, when and how, and they may or may not care about the ethical and legal implications of the whole process. If you're especially unlucky, you're also coming in at the tail end of a whole history of these data consumers being unsatisfied with previous efforts for one reason or another.
So, in an ideal world:
- you get a perfectly sensible list of requirements from your stakeholders
- you know enough about the Blackboard database schema to see what table(s) to query to fulfill them
- you're familiar enough with the Experience API specification to know that the data actually belongs in a Learning Record Store
- you have systems in place to:
- extract live Blackboard data
- transform it into xAPI statements
- load it into a live LRS
- you have infrastructure in place to do the above reliably and on the regular
- you have informed consent from everyone whose data you're extracting
- which actually means: you know whose data you're allowed to extract and whose you're not
Given the above, you can throw together a product, get it up and running in record time, and enjoy the warm fuzzies, total lack of appreciation, and additional unexpected demands that are the unavoidable consequences of a development job well done. (You're the hero the university needs right now, not the one it deserves.)
I'm betting you don't live in an ideal world, though. Hence: this guide.
What this guide isn't about
The short answer: it isn't about points 1 or 6.
What this guide might be a little bit about
Points 2, 3 and 5. I'm going to have to talk about these things in passing, but I'm going to assume you have at least cursory familiarity with:
- the xAPI spec (formerly Tin Can API) and the concept of an LRS, which implies some knowledge of
- RESTful web design
- JSON data
- the Blackboard schema, which implies
- SQL (Oracle or MySQL, since those are the databases Blackboard supports; this guide was written in an environment that uses Oracle)
Also useful to have in the toolbox (but I strongly doubt I'll be saying anything you don't already know, even if you've never actually programmed in either language before):
- JavaScript
- Java
I'm also going to assume you have:
- a workable set of requirements
- an environment you can develop in, which because you're communicating between various data sources also implies
- credentials to query the Blackboard DB
- credentials to GET from and POST to the LRS
- an environment you can deploy to
- ethical permission to do so.
I mention these at all because you're almost definitely a developer at a university, which means you're operating in an enterprisey context, and these things can be major headaches even without institutional roadblocks. If you don't have it in black and white that they're sorted out: godspeed.
What this guide definitely is about
It's about point 4. Of the subset of the problem domain which can't be efficiently solved in hardware or wetware, the biggest problem is getting various systems to talk to each other intelligibly and intelligently. So much so that there's a whole class of tools designed to do just that: ETL tools (Extract, Transform, Load). I'll be showing you how to get the above job done using one such tool: Kettle (the old and much pithier name for what's now called Pentaho Data Integration). Check the above link if you want the sales pitch; here's what's important:
- It's written in Java, so it's very portable; this is the reason why so much of the above is system-agnostic. (For what it's worth, the solutions I've delivered have been developed on Windows and deployed on Linux.)
- It amounts to a visual programming language; I was initially sceptical about developing with something that claims not to require any prior programming knowledge, but don't worry, that's pure Madison Avenue-caliber bullshit.
- The end results (consisting of pretty little GUI flowcharts showing you where your data is coming from, what's happening to it, and where it's going) are actually just XML files, so not only is the tool highly interoperable, your work is too. This is a Good Thing: if you're trying even medium-hard to stick to the spirit of the xAPI spec, then the chances that nobody else will ever use a similar transform are slim to none, and you want to reduce their overhead as much as possible.
- It's open-source. This is a mixed bag: it means Kettle itself is free, and anyone, including you, can contribute by wrapping some idiosyncratic series of transforms in a plugin, further reducing the overhead of implementing something similar elsewhere; however, it also means that the documentation straight-up sucks. Aside from the official literature (which seems to be in two separate but identical places for no readily apparent reason, and is not always wonderfully helpful either way), I am most definitely not the first to write about Kettle on the internet, but you have about as much of a chance to find something usefully relevant through Google as you have to find anything else. (This is the reason why this guide has such a narrow scope.)
So, with no further ado...
A simple Kettle transform
Setup
I'm going to mostly gloss over the process of installing Kettle, for the simple reason that it doesn't actually need installation: you just download it, unzip it, and provided your JRE is up to date it should work straight out of the box. You just run the appropriate batch file/shell script, and you're off to the races. In the first instance, that'll be Spoon, the GUI in which you'll be doing the lion's share of your developing.
One thing you should note, though, is that it requires a few environment variables:

As far as I know, the only one Spoon needs to work is JAVA_HOME (though it will complain at you if the others aren't set), but if I recall correctly Pan and Kitchen (command-line tools we'll be seeing later) need the other two, so you might as well set them and forget about them.
If you're on a High DPI device, you might also want to look up how to make Kettle use an external manifest file to recognize that, so that the GUI elements are big enough to see and use without squinting. I didn't do this, because I don't actually use the buttons, and everything else is just big enough to not be annoying, but YMMV.
If this is all sorted out, Spoon should fire up:
Initial requirements
For simplicity, let's say your requirements are in the form of (appropriately mad-libbed) statements that your stakeholders want to see in the LRS:
Student S took action A versus object O [at time T] [in context C] [with result R]
This is the format I found most useful, because it reflects the xAPI philosophy of allowing form to follow content rather than vice versa, and makes clear what you should be delivering but leaves the how up to you, but YMMV here.
Let's also say that your stakeholders are doing some very simple analytics based on how often students login to Blackboard. The only kind of statement they want to see is:
Student S logged into Blackboard at time T
A note on unit testing
I would have enjoyed writing this guide in a more test-driven style, but unit testing Kettle transforms is technically impossible because of what a transform is and how it works. This is detailed in a series of posts starting here (and a forum post here where the main Kettle guy essentially says "no, you can't really do this"). It's possible to approximate proper unit tests, but this is essentially just a higher-level transform that can't be meaningfully automated, subject to the same chance of human error in its design. So, while the above article's statement that tests are "twice the work" is false for a purely cognitive definition of "work", the lack of meaningful automation means that you do spend twice the time, and the fact that there's no programmatic test suite to logically preclude some human error means (according to my intuitive and probably fallacious grasp of the math) that the average number of bugs goes from n to n². I tried to write declaratively, at least, so you can imagine the unit tests... in your mind, man. If you want to follow the above articles and develop unit tests for all your transforms, more power to you.
Step 1: Extract
Kettle calls the files you design in Spoon transformations (which I've been calling transforms for short); the first thing to do, then, is to create one, and to make sure you can get records from the DB with the information you need.
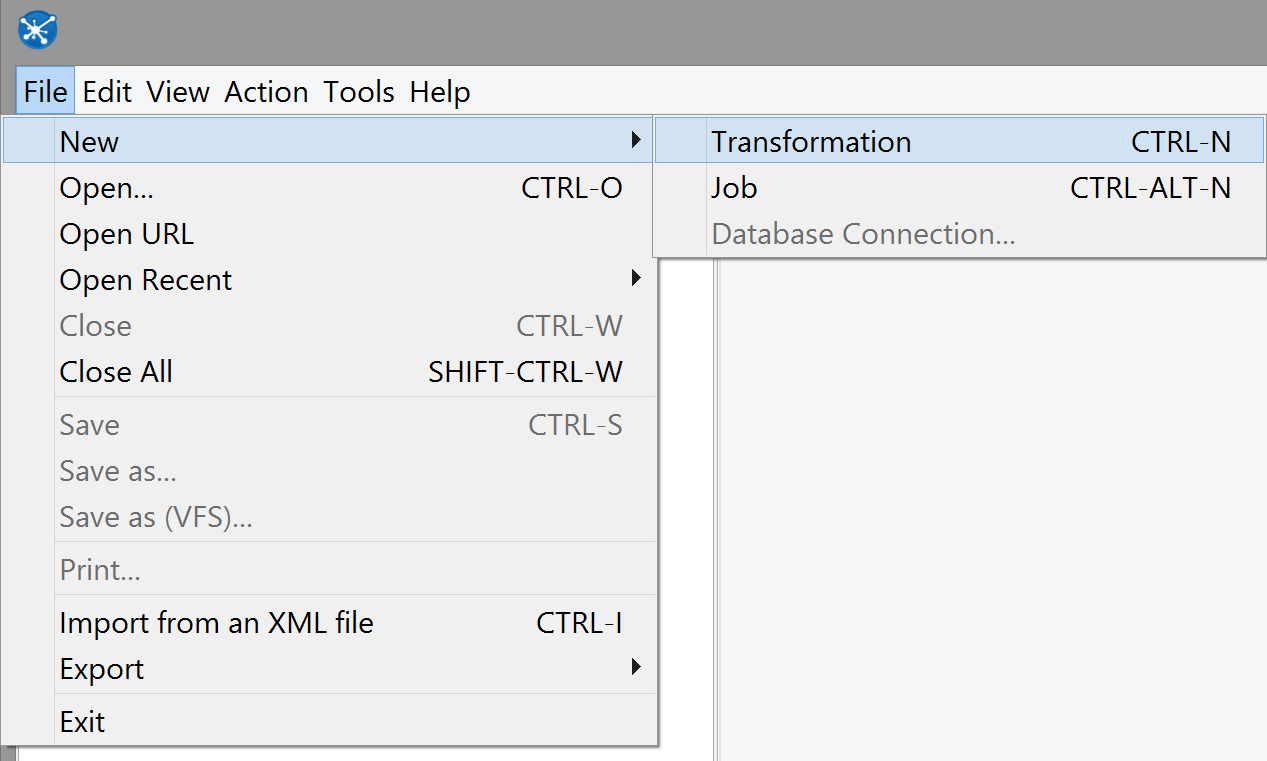
Next, drag a Table input step from the sidebar to the workspace. (You can filter the available steps by entering text in the box.)
To actually write the SQL, I prefer not to use Spoon; if you just want to know if a query will run and return useful data, you don't need to know what happens to the data after that, so there's no reason to run a partially-complete transform. You can, of course, but there's a lot of overhead that I feel slows me down. I like how you can hit
Ctrl+Enterto run a single statement in SQL Developer, but you can also write scripts in your favorite text editor and execute them from the command line. Whatever works.
Above, I said "records with the information you need"; this seems trivially obvious, but I mean it in a way that may not be. (It wasn't to me at first.) Kettle works on rows - that is to say, the fundamental, indivisible unit of data is a single record which is understood to consist of fields. (You can conceptually divide a row into any number of groups of its constituent fields, but if you did this literally in Kettle, what you would have would be new, separate rows with fields that happen to correspond to some degree with the input row.)
What this means is that before you can operate on two items of data as though they were related, you have to make them actually related by making them part of the same row. Kettle only ever "sees" a single row at a time (with the exception of things like Analytic query and Group by steps, which we don't need quite yet), so if you want to construct a statement that says
Student S logged into Blackboard at time T
then you need to get S, T and the datum that a login occurred, in a single row from your query result. As such, we know that the query has to look something like this:
select
user_id,
timestamp
from ???
where event like '%login%'
;Fortunately, as you may or may not be aware, there's a table in Blackboard that gives us most of this:
select
-- user_id,
aa.timestamp
from bb_bb60.activity_accumulator aa
where event like '%login%'
;The particulars of accessing any given table may differ in your environment; at any rate,
activity_accumulatorfalls under theas_coreschema.
It still needs some work, though. We need to substitute event_type for event; however, there are ±7 different values that field might hold, of which the only relevant one is LOGIN_ATTEMPT (which gives us successful as well as unsuccessful logins). So, we also need another filter to only get rows representing successful login events:
select
-- user_id,
aa.timestamp
from bb_bb60.activity_accumulator aa
where aa.event_type = 'LOGIN_ATTEMPT'
and aa.data like '%Login succeeded%'
;
/* figuring out what other information aa.data can hold
is left as an exercise to the reader; this is how it looks
when someone logs in successfully */user_id is commented out because it's an invalid identifier for activity_accumulator; to make it work, we'll need a join with users.
select
u.user_id,
aa.timestamp
from bb_bb60.activity_accumulator aa
left join (
select
pk1,
user_id
from bb_bb60.users
) u
on aa.user_pk1 = u.pk1
where aa.event_type = 'LOGIN_ATTEMPT'
and aa.data like '%Login succeeded%'
;I got used to doing my joins this way while learning SQL because it seemed wasteful to make the DB return the whole row if all I wanted was a couple of fields; however I never actually noticed any difference in performance and it probably takes about the same amount of time even in theory if the tables are indexed. IANADBA, YMMV.
If you try running this you should notice that you also get a bunch of rows corresponding to instructor and administrator logins. That's no good - the target statement is Student S logged in. So, add another filter, and a join to return the data it filters on:
select
u.user_id,
aa.timestamp
from bb_bb60.activity_accumulator aa
left join (
select
iu.pk1,
iu.user_id,
ir.name as role
from bb_bb60.users iu
left join (
select
pk1,
regexp_substr(role_name,'[^\.]+') as name
/* this regexp is because the value of this field is sometimes
given as a stringified Java property: 'role.name' where we're
only interested in 'role' */
from bb_bb60.institution_roles
) ir
on iu.institution_roles_pk1 = ir.pk1
) u
on aa.user_pk1 = u.pk1
where aa.event_type = 'LOGIN_ATTEMPT'
and aa.data like '%Login succeeded%'
and regexp_like(u.role,'student','i')
;More SQL idiosyncrasy: I prefer to scope my joins to where they're relevant, so
institution_rolesgets joined tousersrather thanactivity_accumulatorbecause it's related to the user-identifying part of the row rather than the activity or the row itself. Seeing where things come from helps me keep it all right-side-up in my head, but the query would still work if it was rewritten to be flatter. As always, YMMV.Also, I'm using regexps here because in my environment, there are a number of records in the
institution_rolestable for which therole_idis not specific enough and therole_nameis too descriptive. They all include the word "student", though, so I want the rows that match that case-insensitively (the third argument toregexp_like()is a mode string like you'd find on a "canonical" regexp). This is just defensive design, in case someone starts using different roles or more are added to the DB. Alternatively, if that's unlikely, you could replaceregexp_like()with a straightforwardu.role in (role1, role2, ...)- whatever works.
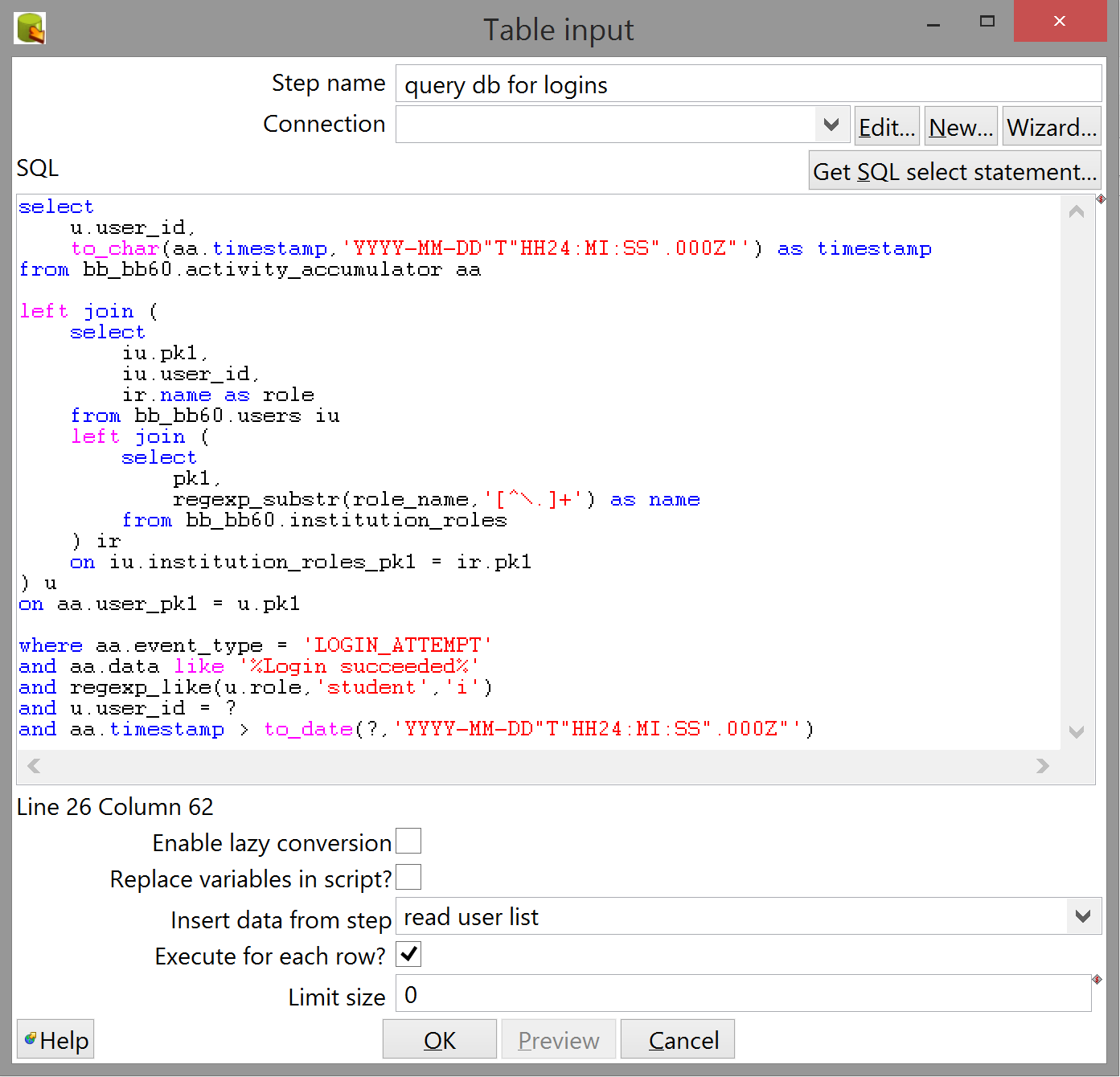
Your query should now be sufficiently rigorous; open the Table input step configuration in Spoon by double-clicking it and copy-paste the SQL in. IMPORTANT: Kettle doesn't expect more than one SQL statement per Table input step, so it'll choke on the terminating semicolon if you don't remove it. This is also a good time to give the step a more descriptive name.
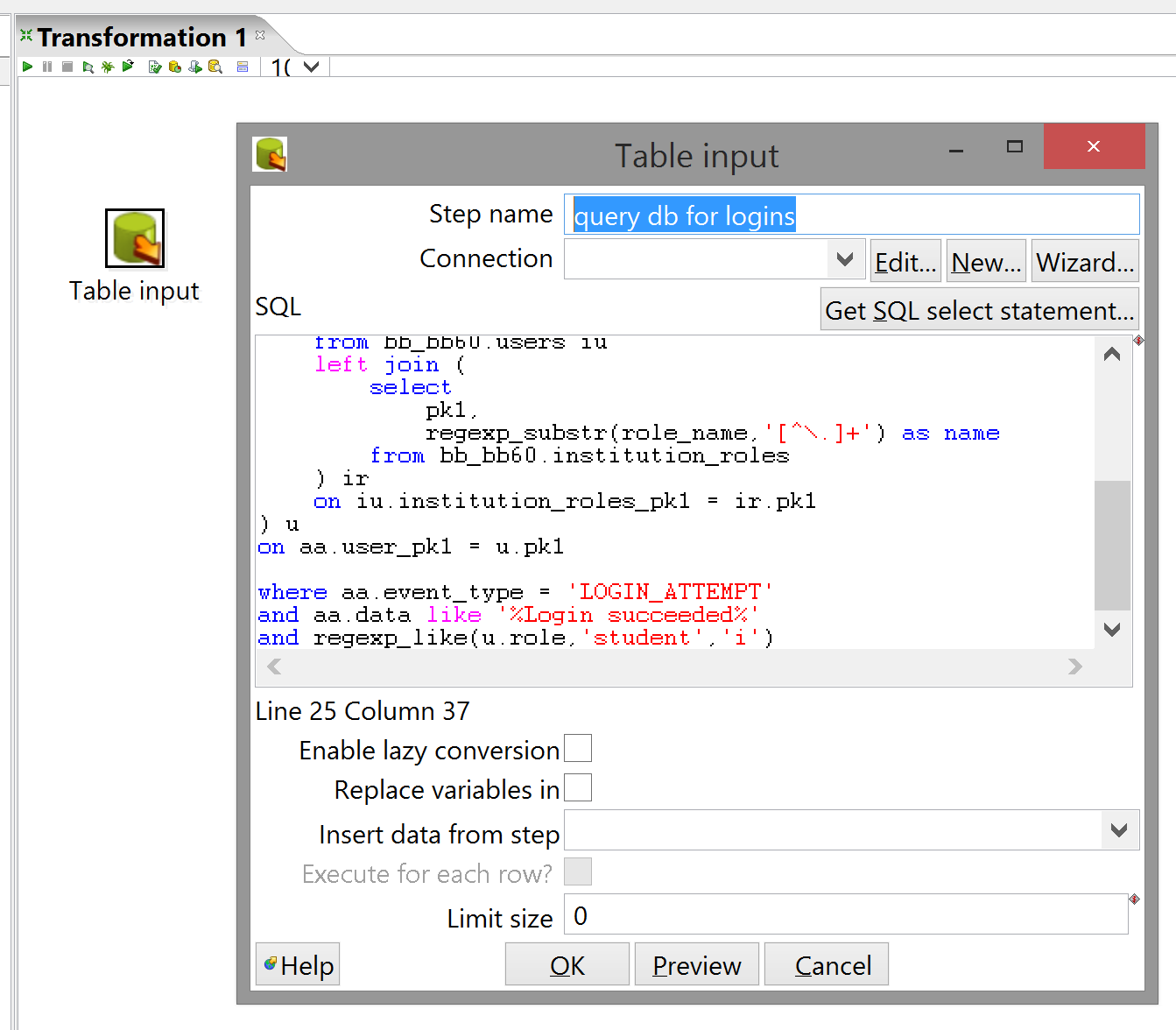
If you try to press "OK" now, Kettle will complain that you haven't selected a database connection. You can either create one of these by right-clicking the appropriate sidebar item and selecting "New", or by clicking the "New..." button in the Table input step. They both lead to the same dialog:
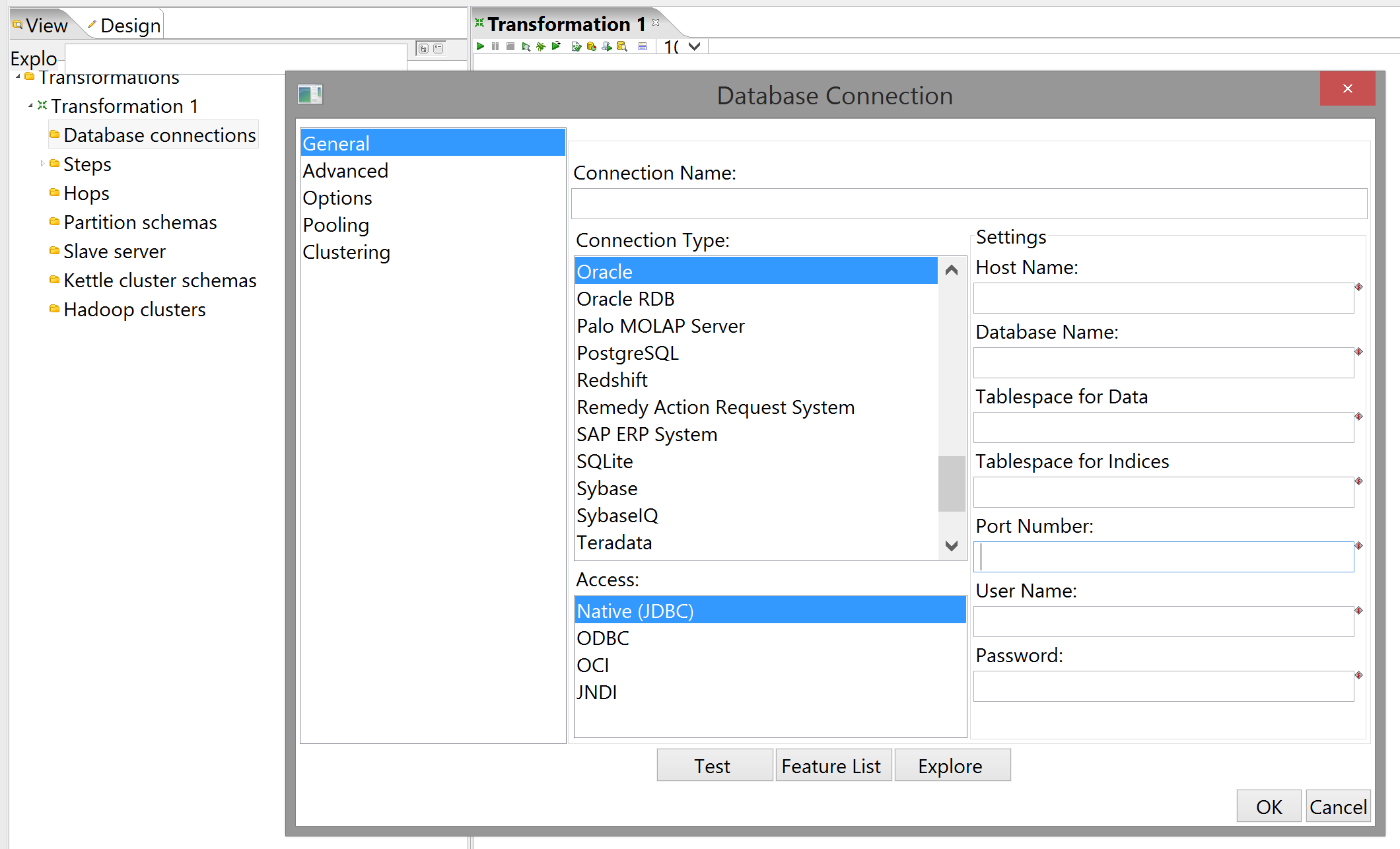
Fill in your details and credentials here. One stumbling block I encountered here (with which the docs were unhelpful) was that "Database name" is straight-up mislabeled and actually refers to the database instance name, which you should be able to find in the Blackboard frontend admin console.
If you're developing at the University of Amsterdam, you probably have access to the transforms I already wrote, so save yourself a lot of institutional headache: make a copy of a transform that uses a DB connection and delete all the steps, then save that somewhere under a different name. The underlying XML should still contain the connection information for dev and production DBs, which you can use in Table input steps as described above.
Step 2: Transform
Now that we're receiving the correct rows from the DB, the next step is to generate a well-formed xAPI statement around them. I chose to use JavaScript for this; it could have been done a couple of other ways (the Json output step springs to mind, since you will eventually be POSTing JSON data to the LRS) but I prefer to have precise control over my JSON without interposing a bunch of interface layers.
Kettle does a fair bit of work for you under the hood; for instance, if you drag a Modified Java Script Value step to the workspace...
...link it with the finished query step (shift-click on query db for logins and drag to the new step - the Kettle term for the resulting link is a "hop")...
...and open it up for configuration, you should see "Getting fields...please wait" in the left sidebar under "Input fields" for a moment before the fields appear from the query we just designed, as Kettle runs the query to make sure it's valid and to decide what fields to show you.
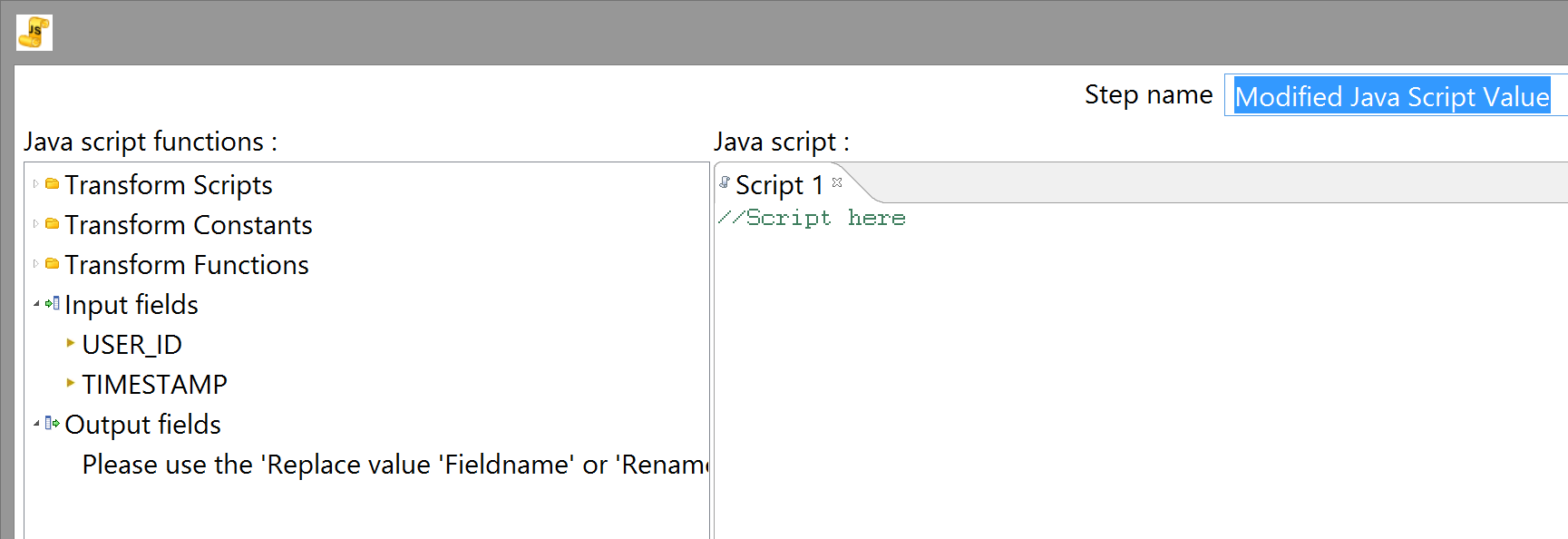
Incidentally, "Modified Java Script Step" is also a misnomer at this point. Presumably there was once a different kind of JavaScript step, and they presumably existed side-by-side for a while, but now there's just this one, so "modified" is misleading - it's just JS. It also doesn't return a single value; it returns as many as you like, as new fields on the rows that pass through it. UI is not Kettle's strong suit.
xAPI statements are just JSON strings, so the main part of any step that turns a row into a statement is essentially going to be one big concatenation. When designing more complex transforms including JS steps that generate more than one type of statement, you'll need to include a little logic, but our requirements are simple enough that we don't need to do that here.
This is the part where agreements made with your stakeholders come into play; the LRS, by design, doesn't much care what content you give it, as long as the content is formatted correctly. So, if you want your data to be consistent both internally and with stakeholders' expectations, you should agree with them on a recipe/namespace/IRI schema for the statements you'll be generating. Let's say you agree that your statements should:
- use the
accountobject as the inverse functional identifier (IFI) for theactorproperty - use the standard
activityTypeandverbIRIs as listed on the xAPI/Tin Can Registry - include a
contextspecifying that the action took place on Blackboard
You might end up with JSON looking something like this:
{
"actor": {
"objectType": "Agent",
"account": {
"homePage": "https://secure.uva.nl/",
"name": "whoever"
}
},
"verb": {
"id": "https://brindlewaye.com/xAPITerms/verbs/loggedin/",
"display": {
"en-US": "logged in"
}
},
"object": {
"objectType": "Activity",
"id": "https://blackboard.uva.nl/",
"definition": {
"name": {
"en-US": "Blackboard Learn"
},
"type": "http://id.tincanapi.com/activitytype/lms"
}
},
"context": {
"platform": "https://blackboard.uva.nl/"
},
"timestamp": "whenever"
}n.b.: all of this (and more) is documented - rather better than Kettle, not that that's hard - in the xAPI specification.
Obviously, we need to replace "whoever" and "whenever" with the fields from the DB query. This can be done in one of two ways; when I started developing Kettle transforms, the JavaScript JSON library hadn't been included with the engine that Kettle uses to run the JavaScript we're about to feed it (or at least that's my best guess at why it didn't work when I tried to use it), so I ended up having to literally concatenate the fields into the statement like so:
var statement = '{\
// ... \
"timestamp": "' + TIMESTAMP + '"\
}';That is, you assign a string literal (so that you can use quotes with impunity), cut a hole in it right between the quotes around the value of the property you're inserting, and concat the DB field as it's listed under "Input fields". (With liberal application of backslashes to keep everything readable, of course.) These are case-sensitive; if you double-click the name on the left, it'll insert it into your script at the cursor.
In the meantime, though, the JSON interface has been included, so instead we're doing this:
// because of how Kettle implements rows and fields as objects,
// you have to explicitly coerce input fields to strings before assigning
// or you'll get a Java error that the field doesn't have a method "toJSON()"
var data = JSON.stringify({
actor: {
objectType: "Agent",
account: {
homePage: "https://secure.uva.nl/",
name: new String(USER_ID)
}
},
verb: {
id: "https://brindlewaye.com/xAPITerms/verbs/loggedin/",
display: {
"en-US": "logged in"
}
},
object: {
objectType: "Activity",
id: "https://blackboard.uva.nl/",
definition: {
name: {
"en-US": "Blackboard Learn"
},
type: "http://id.tincanapi.com/activitytype/lms"
}
},
context: {
platform: "https://blackboard.uva.nl/"
},
timestamp: new String(TIMESTAMP)
});There's arguably an even better way to do it. The Modified Java Script Value step lets you add multiple script tabs; you have to designate one of them as the "Transform script" (meaning it gets executed once per row, with the data from that row), and you can designate others as the Start script and End script, which get executed only once for every run of the whole transformation. This means you can initialize the barebones statement object in the Start script, then fill in the blanks and stringify it in the Transform script. Like so:
// Start script var skeleton = { actor: { objectType: "Agent", account: { homePage: "https://secure.uva.nl/", name: "" } }, verb: { id: "https://brindlewaye.com/xAPITerms/verbs/loggedin/", display: { "en-US": "logged in" } }, object: { objectType: "Activity", id: "https://blackboard.uva.nl/", definition: { name: { "en-US": "Blackboard Learn" }, type: "http://id.tincanapi.com/activitytype/lms" } }, context: { platform: "https://blackboard.uva.nl/" }, timestamp: "" }; // later assignments shouldn't affect the skeleton: function clone (obj){ return JSON.parse(JSON.stringify(obj)); } // Transform script // clone the skeleton var statement = clone(skeleton); // mad libs statement.actor.account.name = new String(USER_ID); statement.timestamp = new String(TIMESTAMP); // ready to send var data = JSON.stringify(statement);This may have some performance costs, which may or may not be worth it considering the additional encapsulation and maintainability. YMMV.
So now that the code is sorted, we want to make sure the step is sending the correct output (in this case, the finished statement as a JSON string). That's what the table at the bottom of the step configuration dialog is for: click "Get Variables" and it'll populate itself with all the variables you declared in the currently selected script tab. (It occasionally gets the type wrong, but you can change that manually. You don't even have to use "Get Variables"; just don't typo when entering the variable name you want to pass as an output field.)
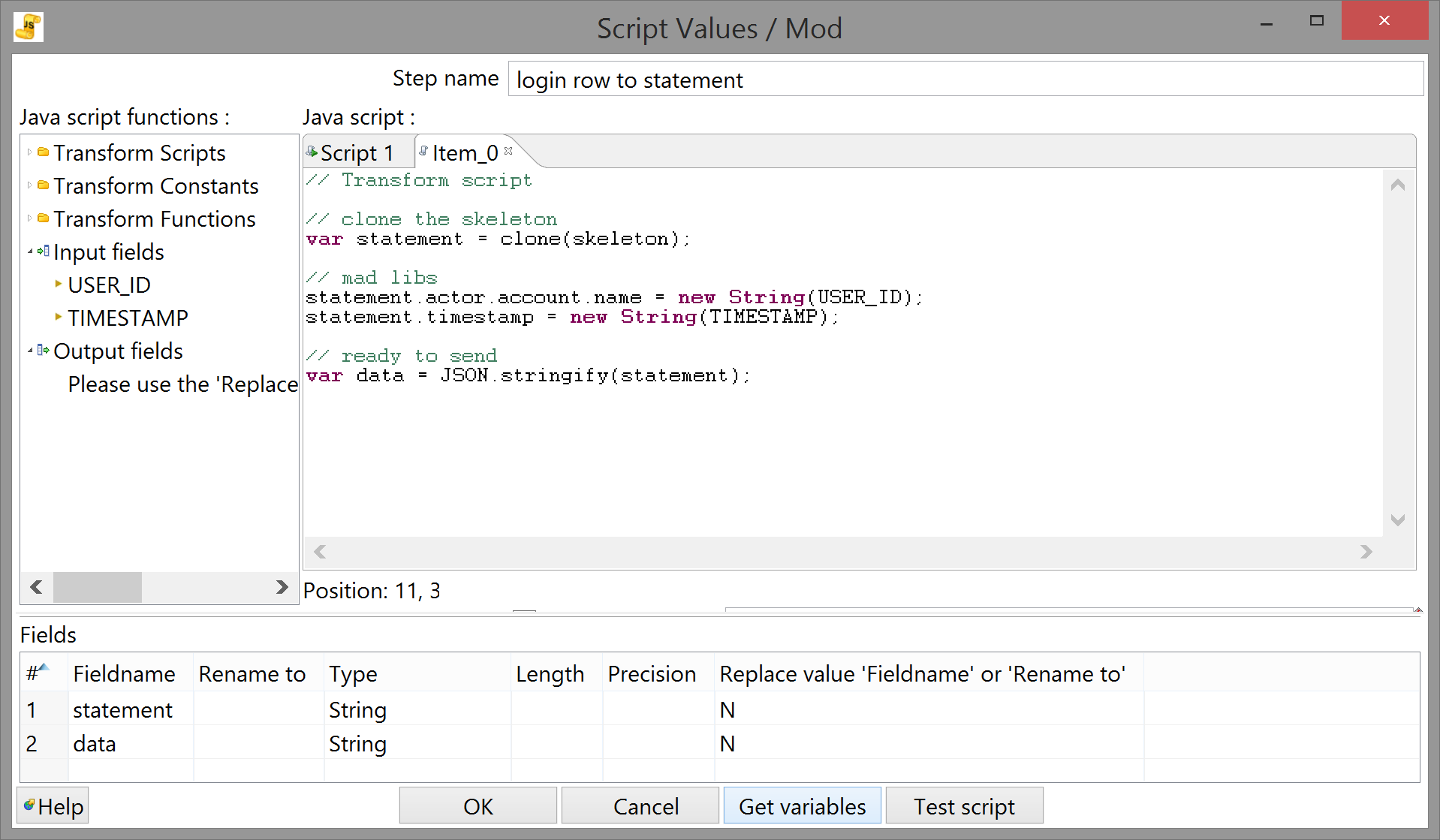
Obviously, we don't need statement in there, so click its row number to select the whole row, delete it, and click "OK" to return to the workspace (after giving the new step an appropriate name as well). If you right-click on the JS step and select "Show output fields" you'll see that in addition to the field you told it to output, it's also passing through all the fields from the previous step. This isn't a disaster, but it's something to be aware of, especially since:
- a step which tries to add a field to a row that already has one with the same name will automatically (and silently) change the name to
field_n(wherefieldis the name andnis how many fields of that name the row already has) - it's not always clear or intuitive which steps pass through everything and which don't.
This can result in subtle and annoying bugs if you don't expect it. If you need explicit control over which steps get passed, though, you can use a Select values step, which gives you exactly that.
Step 3: Load
We're almost done with a basic transform - the last part is to send our finished statement to an LRS. Since it's just a REST service, you'll need a REST Client step:
This one doesn't involve any code, it's just a dialog box with various configurable options.
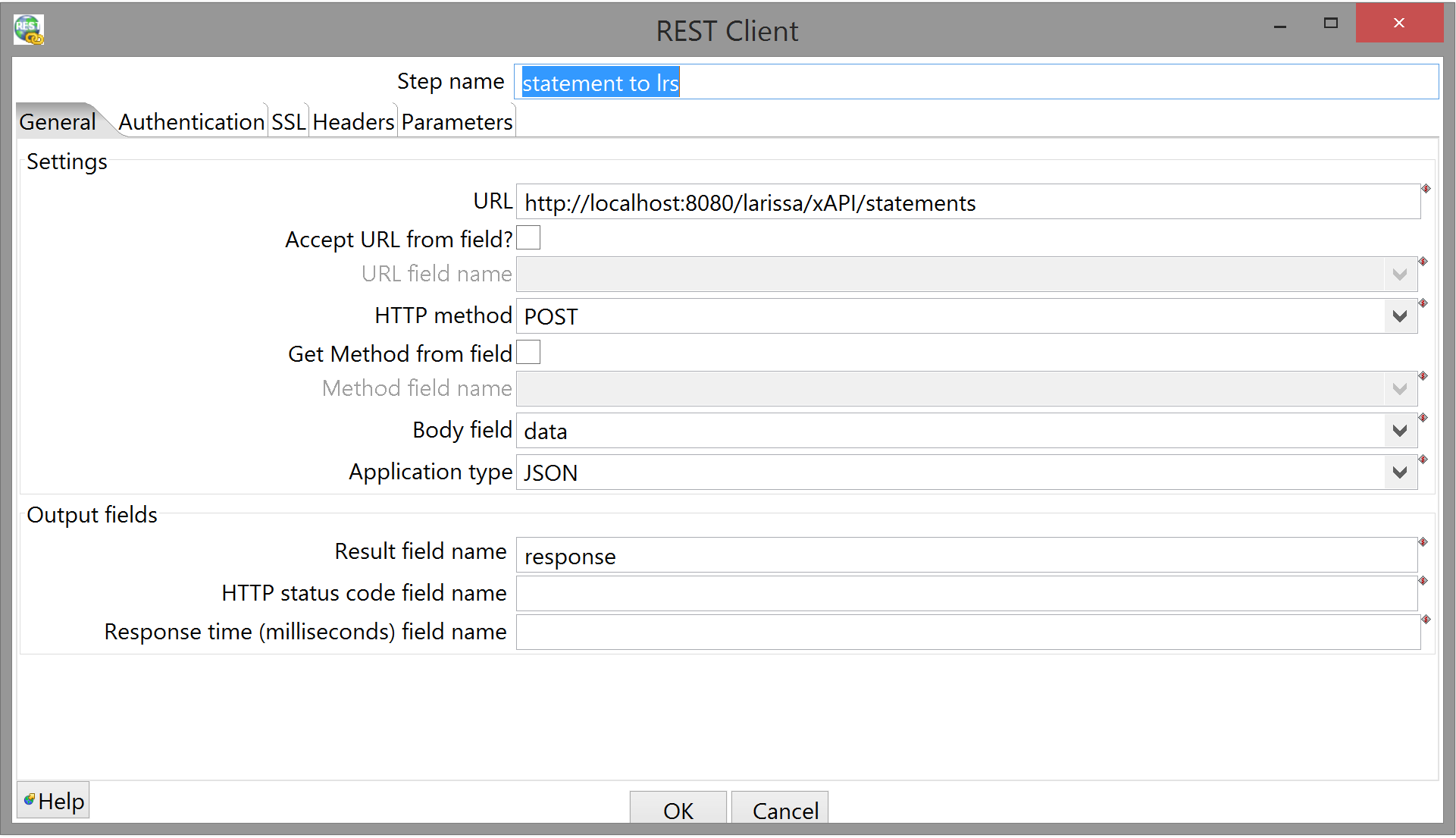
Things to pay attention to:
- General tab:
- URL: Here, I'm using a local instance of the Apereo Learning Analytics Initiative LRS, Larissa, for development purposes (and so I didn't have to keep bugging the guy who coded it). You can find the GitHub for Larissa, with a readme detailing how to build and deploy, here. Alternatively, you may have a dev LRS set up somewhere.
- Method: POST.
- Body field: make sure you select the correct one from the drop-down menu.
- Application type: JSON.
- Result field name: can be whatever you like.
- Authentication tab:
- Login/password: whatever your LRS is configured to accept - instructions on adding users are also in the above readme.
-
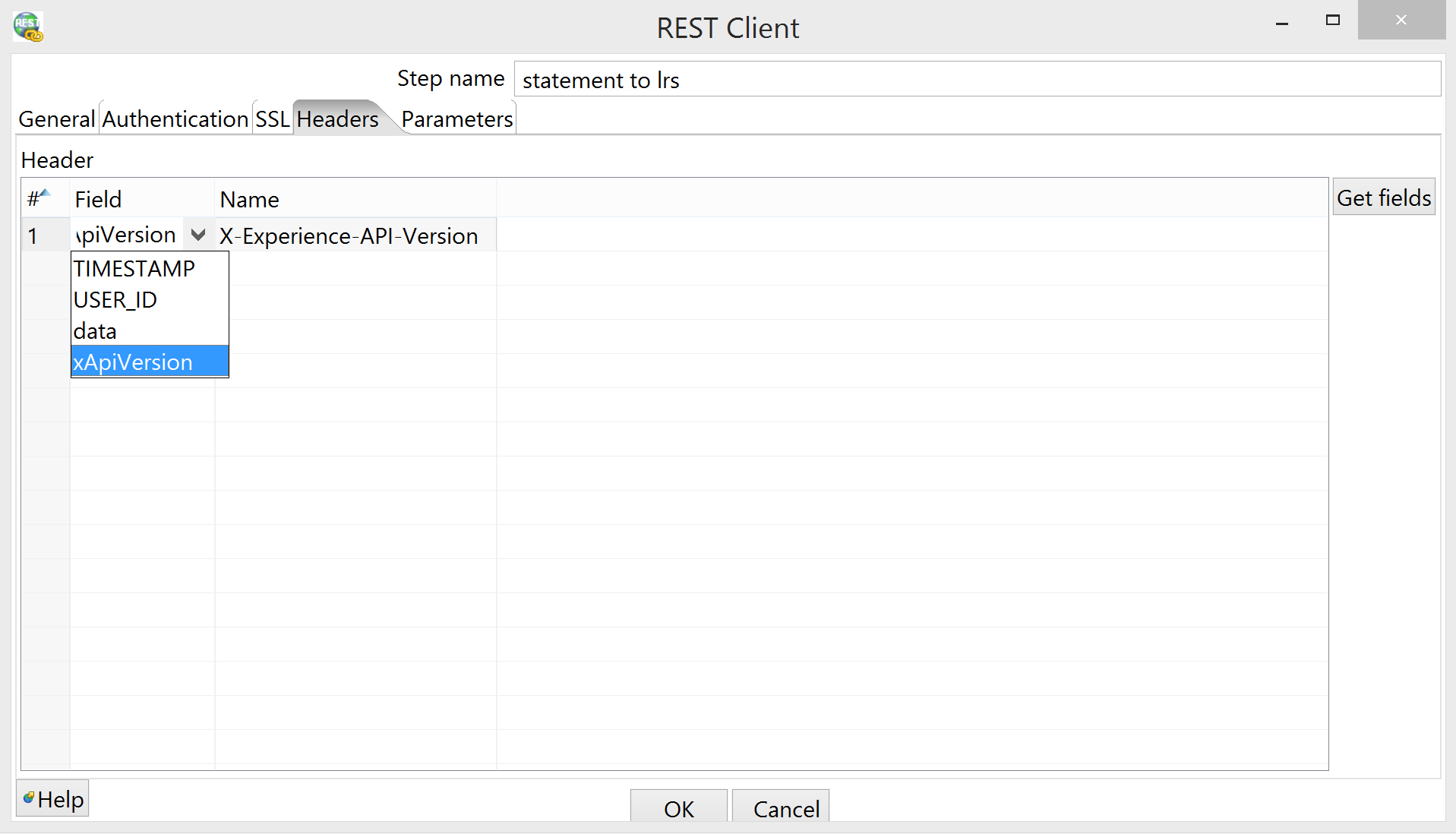
Headers tab: if you're familiar with the xAPI spec, you'll know that you have to pass an
X-Experience-API-Versionheader with any HTTP request to an LRS; for some stupid reason, however, you can't set HTTP headers (or parameters) declaratively in Kettle; you have to pass them to the REST Client step as fields. It doesn't matter where they come from; that is, you can either do this:select '1.0.1' as xapi_version, -- ... from bb_bb60.activity_accumulator aa -- ...
or you can do this:
// ... var data = JSON.stringify(statement); var xApiVersion = '1.0.1';
I put it in the JavaScript step, for the same reason that I scope my SQL joins (that is, the version is relevant to the processing of the statement, which only gets produced in the JavaScript step), but YMMV as always. Whichever way you do it: the input field you select from the drop-down box in the Headers tab becomes the header value, and the table cell next to it becomes the header name.
Vitamins done Requirements implemented, what now?
Technically, the transform is finished now - you can run it and it'll function. It could still use a little work, though. For one thing, you'll want to know if you configured everything correctly; also, you're getting all the login events from Blackboard, while maybe some students didn't consent to you extracting that data.
Logging
This one is pretty simple: all you need is a Write to log step.
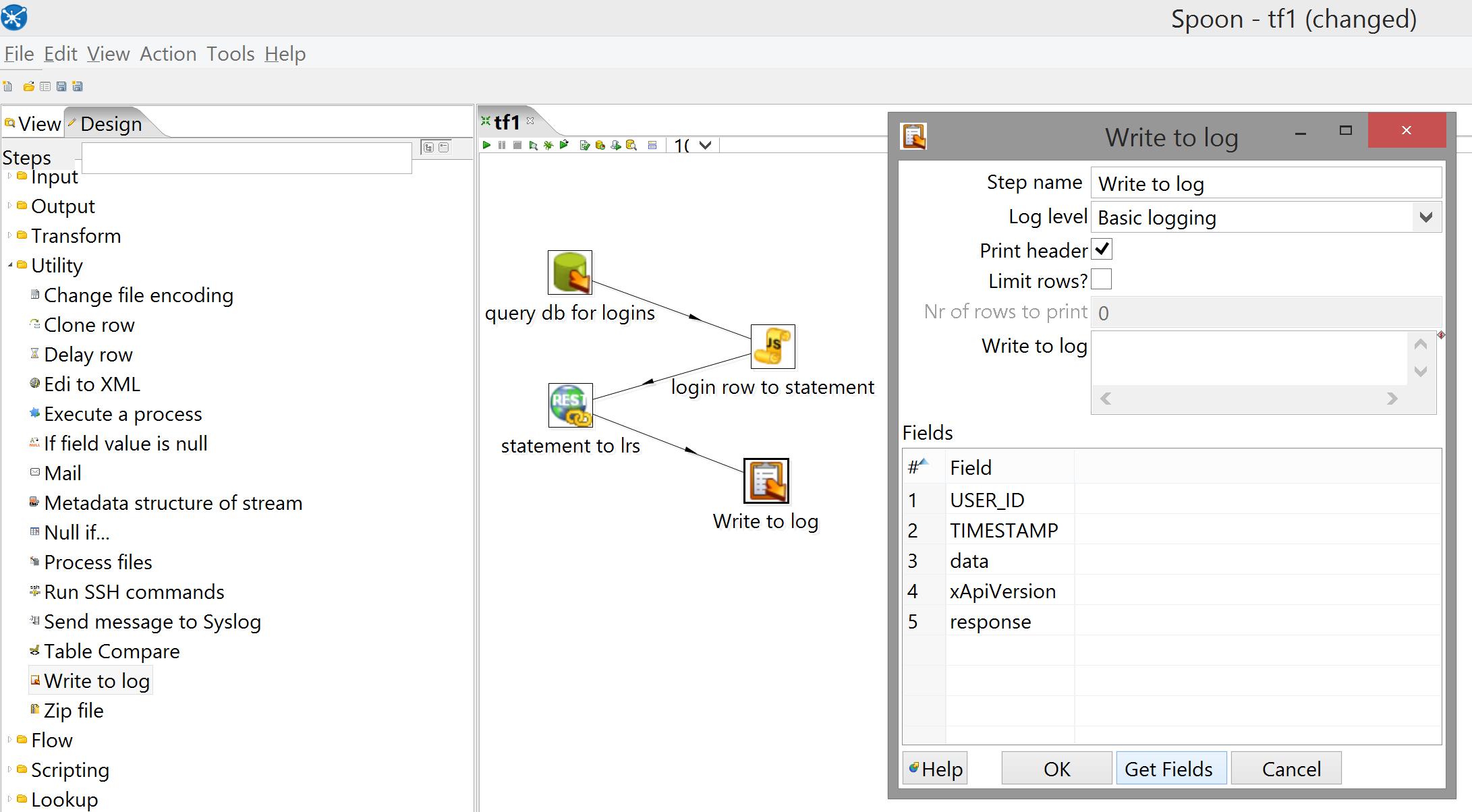
This step is also useful for debugging purposes, but it has a caveat: it doesn't just automatically log whatever fields it's passed. If you have a step that's passing rows with, say, field_x and field_y, and you hook it up to a Write to log step, you have to open said step and click "Get Fields" so that it can see what options it has to choose from (which you can then trim if, for instance, you don't want to see field_x). If, later, you add field_z to the rows passed to Write to log, it (perhaps obviously) won't log that until you "Get Fields" again, but even more annoyingly, if you instead change field_x to field_z in the input it'll actually fail with an error because the Write to log step no longer sees the field_x it's expecting.
Consent
This one is slightly trickier. You have a list of students whose data you're allowed to extract, but you probably got it directly from your stakeholders - there's not guaranteed to be a way to get that same list out of Blackboard programmatically. (And if there is, it's probably going to make your query much hairier.) So, you need to make Kettle read whatever input you might want to give it.
Unfortunately this isn't quite as easy as in your favorite programming language here, but it can still be done with a modicum of effort. Though you can pass arbitrary strings (including filenames) as arguments to a Kettle transform via the command line, there's no way to read a file directly into a step based on command-line input. So, we'll have to get the argument from the process first and read from the file based on that.
The first thing you'll need is a text file with the consenting students' IDs. This can be formatted any way you like; for simplicity, though, I prefer a file with each ID on its own line, like so:
student_id1
student_1d2
etc_etc_etc
student_idn
Annoyingly, Kettle isn't quite smart enough to understand relative paths (which may have something to do with the fact that Kettle's CLI tools are just batch file/shell script wrappers around a .jar file that lives elsewhere), so you have to give it the full path of any filenames you want to pass in as arguments - including the filenames of the transforms you're running. Tab-completion makes this fairly quick on Linux; if you're on Windows, though, it's probably a total crock of shit, so here's a PowerShell script I bashed together/found somewhere (can't quite remember which):
function Full-Path { param( [string]$Item ) ($pwd.path+$Item.substring(1)) }Save this in your PowerShell folder, and then add the following lines to your PowerShell profile:
. C:\Users\you\Documents\WindowsPowerShell\Full-Path.ps1 Set-Alias fp Full-PathThen re-start your shell and you should be able to get the full path of a file like so:
(fp .\a_file_that_lives_here.ext)
Once you have the text file, add these two steps to the transform:
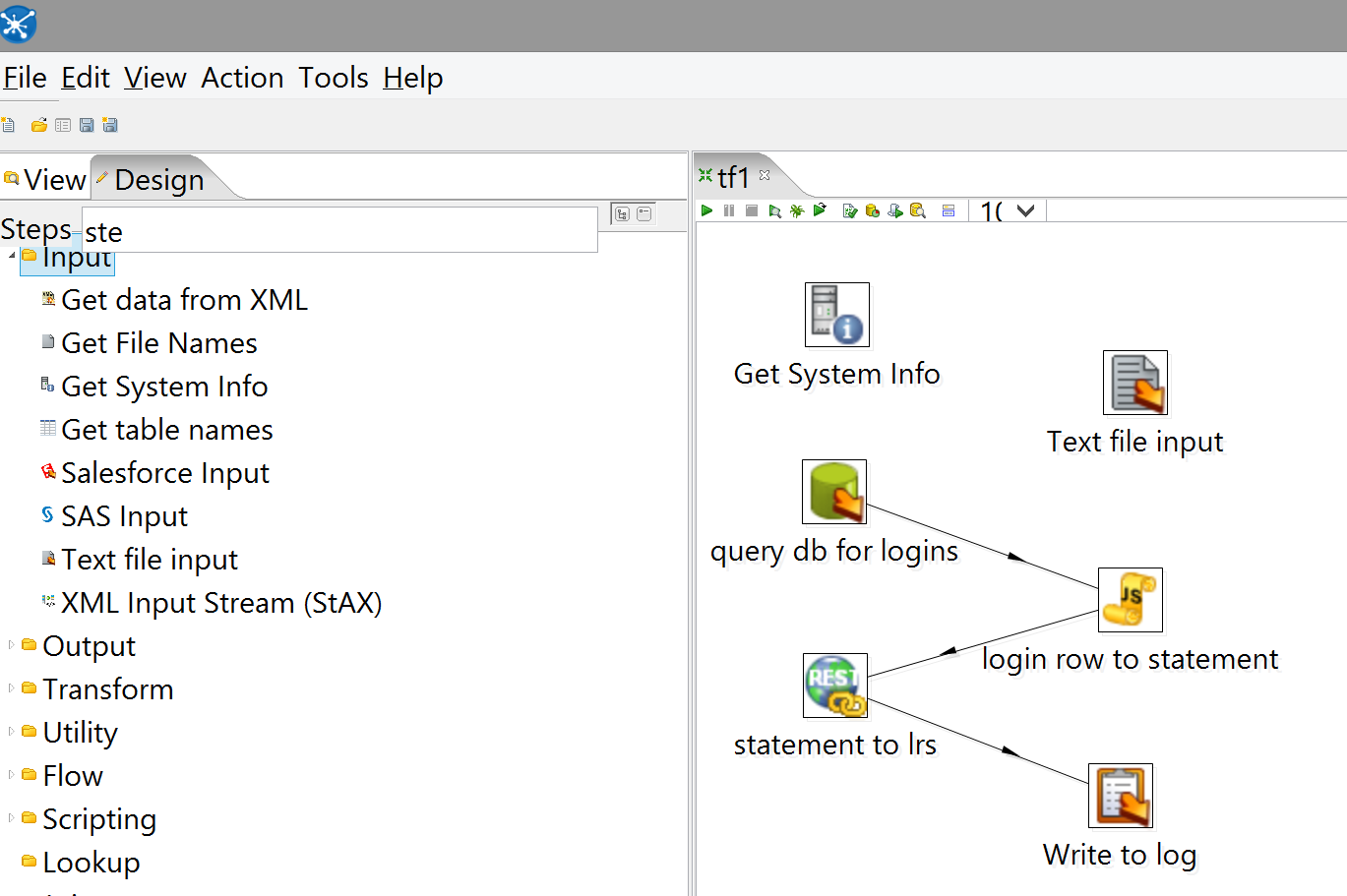
Configuring Get System Info is straightforward; you just have to tell it what you want and what to call it:
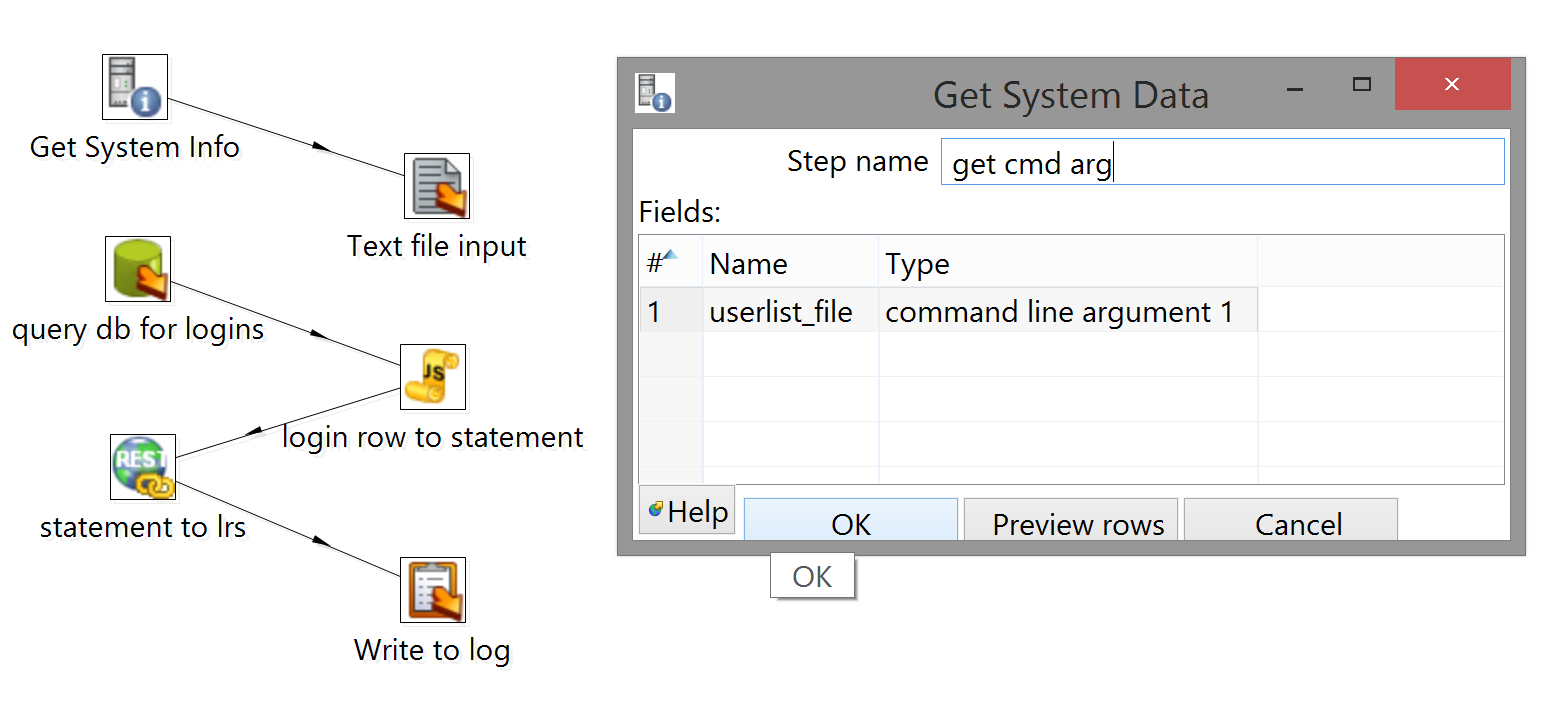
Configuring Text file input is slightly more annoying, though it helps to realize that Kettle still expects to see rows and fields in whatever file you read in.
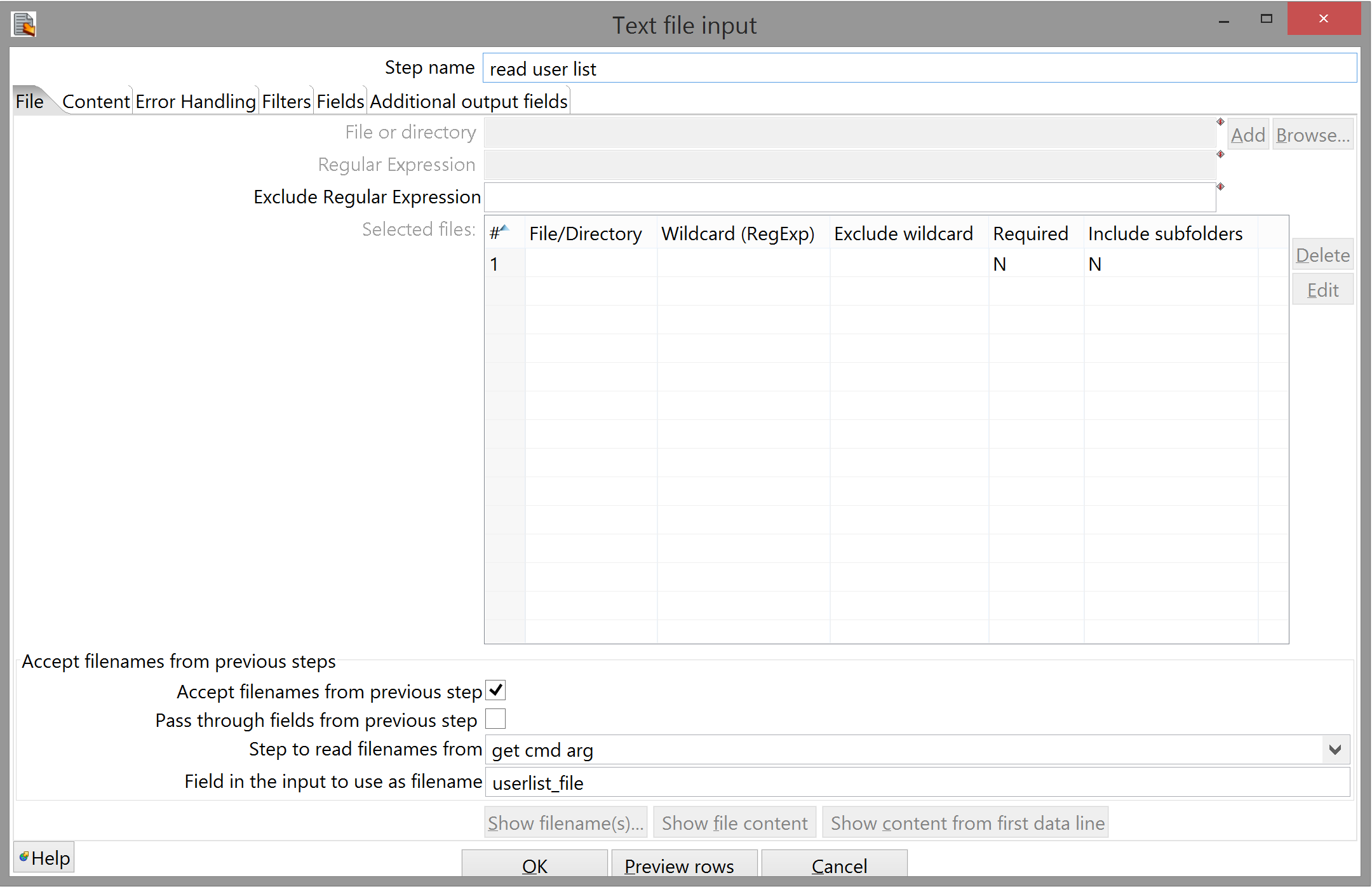
The File tab is straightforward enough, though. Checking "Accept filenames from previous step" grays out the entire upper two-thirds of the dialog; there should only be one option in the "Step to read filenames from" drop-down box; the only moderately stupid thing is that you have to manually input the field name - there's no drop-down box here, or a button to automatically get the step's input fields. (Because it wouldn't be open-source if there weren't a few unnecessary chances for bugs to slip in, I guess.)
There are way many options to configure in this step, most of which you fortunately don't have to touch. Some things to pay attention to, though:
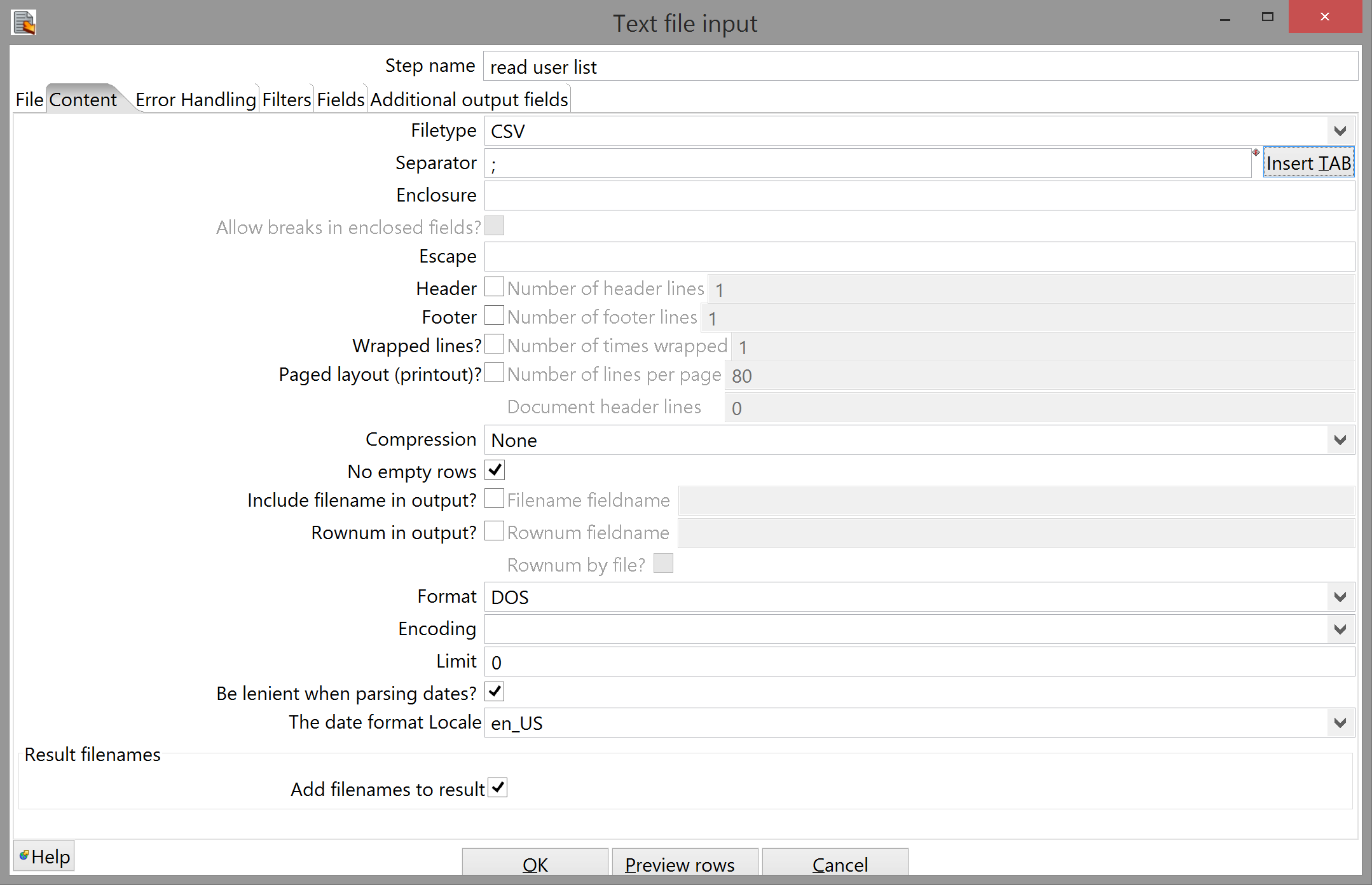
- Kettle has lied to you again: the step is called Text file input, implying you can read in arbitrary text files, but actually the only two formats it accepts are CSV and fixed-width CSV. This means that while our list of student IDs will be parsed just fine, Kettle is actually treating it as a CSV file with only one field.
- As such, you can leave the "Separator" option alone here; it doesn't matter what it is, as Kettle will never see one.
- You have to clear the "Enclosure" field, though. Alternatively, you could wrap each student ID in quotes, but that's unnecessary.
- You also have to uncheck "Header". Again, you could also add a header to the file, but the goal here is to make it easy to change the inputs - if you were going to hardcode everything about this file, you could have just input the filename manually in the File tab. (I developed this habit because, as mentioned, I deployed to Linux - specifically, a server where I had no desktop, so the only way to change a transform in production was to edit the XML itself. Modularity is a Good Thing anyway, though.)
- Everything else in this tab you can leave as-is. It shouldn't give you any trouble.
The last thing you need to do is tell Kettle what you want to call the single field it's reading from your text file; "Get Fields" won't work here, because the pre-processing that determines the incoming field names doesn't include generating command-line arguments, so just input a name and a type in the Fields tab, click "OK", and connect the step to query db for logins:
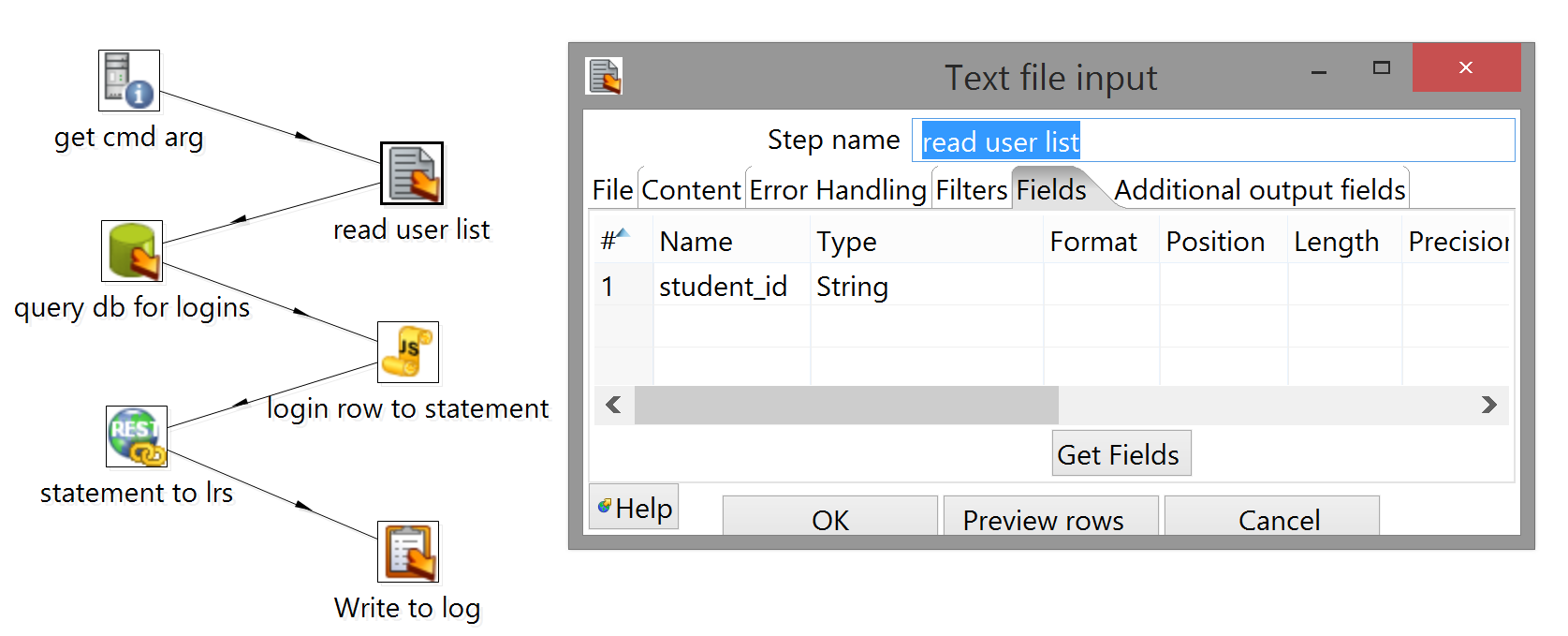
Speaking of which: we'll have to edit that step if we want to make use of the ability to programmatically configure the query.
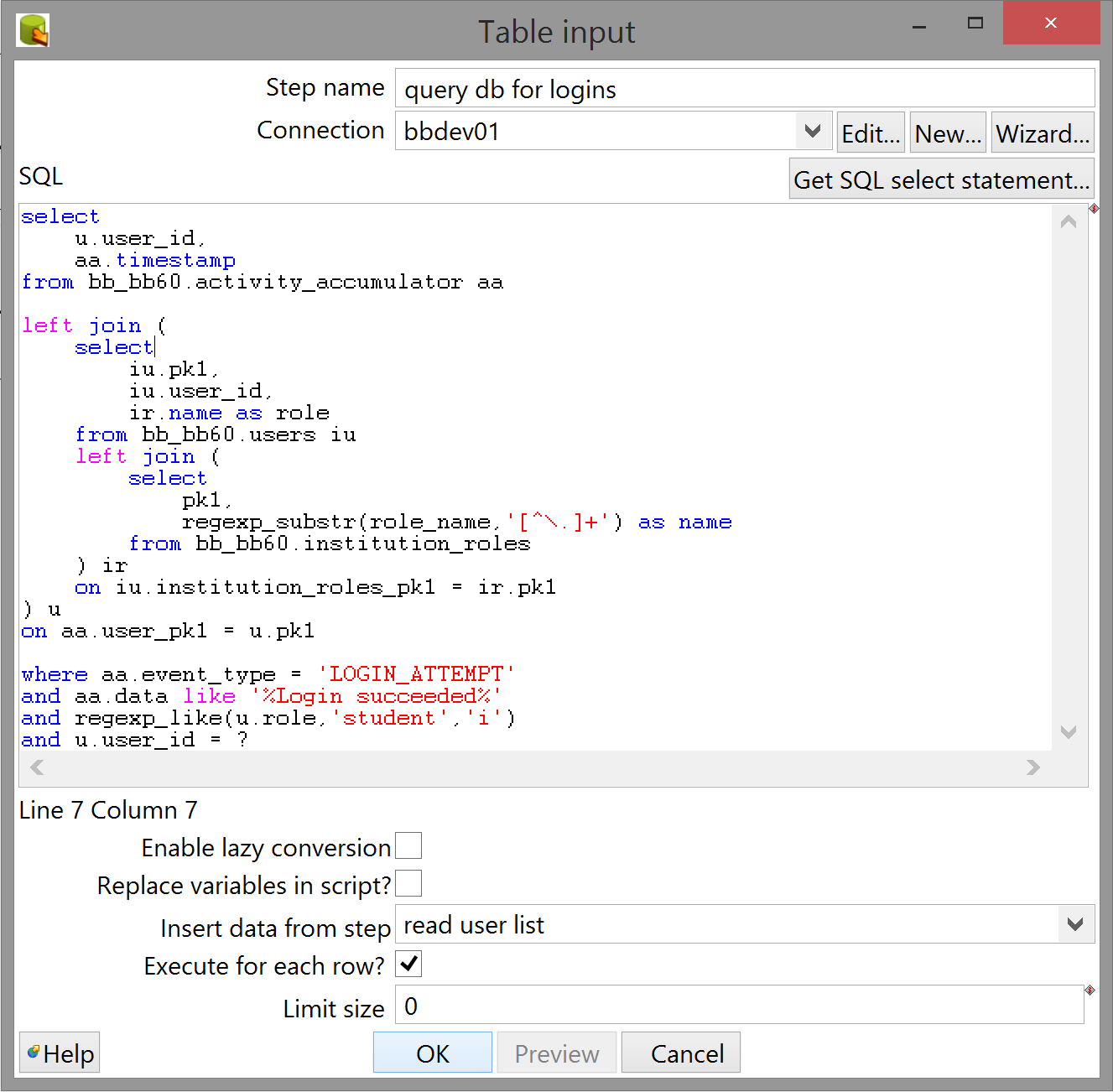
We're doing three things here:
- Selecting a step from the "Insert data from step" drop-down - it should show the recently connected read user list step.
- Checking "Execute for each row" so that we process all the IDs in the file.
-
Adding a line to the query:
-- ... and regexp_like(u.role,'student','i') and u.user_id = ?
If you've done the previous two things, adding a question mark where the DB expects to see a single term will make Kettle programmatically fill in the value from the appropriate step. This happens in top-to-bottom order at both ends: if you right-click the previous step and select "Show output fields" you should see a table with a certain order. This is the order that the Table input step will follow when filling in the blanks. It doesn't matter if a particular question mark is nested ten levels deep inside the query; if it's the first one Kettle comes across when reading the SQL top-to-bottom, it'll receive the value of the first field in each incoming row. (This doesn't matter now because we only have one field in the incoming row, but it's something to keep in mind.)
n.b.: "Replace variables in script" sounds like the above is what it does, but (surprise, surprise) it actually does something slightly different: it allows you to use variables defined elsewhere (including other transformations, which we'll be writing later on).
Deploying
So, the transform is finished; it implements the necessary functional requirements and it's configurable for a variable list of consenting participants. Time to run it. Make sure to save your transform, then start a terminal and navigate to the folder where you keep it.
The command-line tool to run a single transform is called Pan. On Linux the appropriate shell script is pan.sh; on Windows it's the batch file Pan.bat. I added the Kettle directory to my PATH, but you can also run it by name; whatever works.
Either way, you'll need to set a few options before passing the name of your transform and the student list:
-
noreptells Kettle not to use a repository (which is a good idea because repositories are buggy and not well-maintained) -
filetells Kettle you want to pass in an XML file as the transformation to run.
There are several more options which you may find useful; invoke Pan with no arguments to see them.
# Linux
$ sh ~/data-integration/pan.sh -norep -file /full/path/to/tf1.ktr /full/path/to/studentIDs.txt
# Windows
> pan /norep /file (fp .\tf1.ktr) (fp .\studentIDs.txt)
Kettle will throw a lot of superfluous boilerplate log at you:
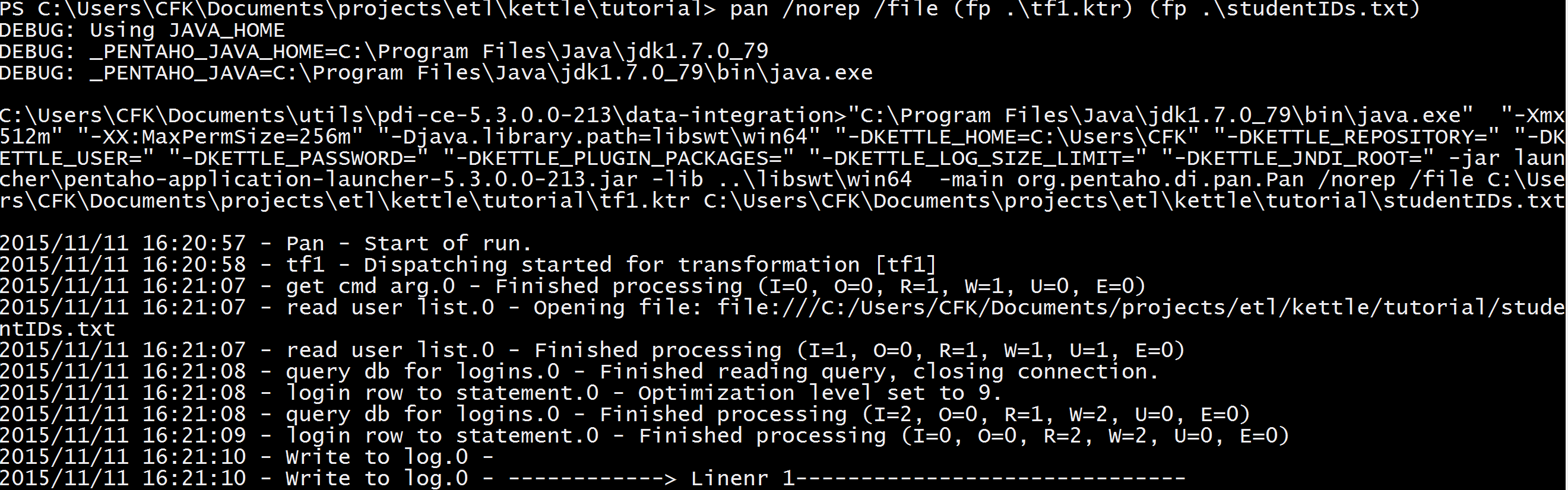
You generally only have to start paying attention when the Write to log step starts talking; in any case, though, this is the part where you start getting errors if things are configured incorrectly. For instance, the first time I ran this I got a JSON error from the LRS (which is helpfully sent back as the HTTP response, and therefore logged by Kettle as the value of the response field in Write to log) because I forgot to camel-case "homePage" in the statement skeleton object.
Once I fixed that, I started getting a different JSON error (so if you're following along then you should be getting it as well); the format of a timestamp stringified exactly as the DB supplies it is apparently not one the LRS is prepared to accept:

There are, as usual by this point, several ways you can fix this; I prefer to take care of it in the DB query, for reasons you can probably guess by now. You'll find, though, that every dialect of SQL has its own pecularities as regards datetime format elements; a quick dip into the Oracle docs reveals that if this is the format expected by the LRS (and I picked this one because it's ISO8601-compliant, which is never a bad idea):
"yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"Then this is the change I have to make to the query:
select
u.user_id,
to_char(aa.timestamp,'YYYY-MM-DD"T"HH24:MI:SS".000Z"') as timestamp
/* yes, we're losing fractional seconds here; it should actually be
'...:SS.FF3"Z"', but for some stupid reason our Oracle installation
chokes on the FF[1-9] format element, despite it being documented
quite clearly. ymmv. */
from bb_bb60.activity_accumulator aa
-- ...Run the transform again and all is well (the LRS sends the UUID of any statement it accepts as the response to the HTTP request which created that statement):
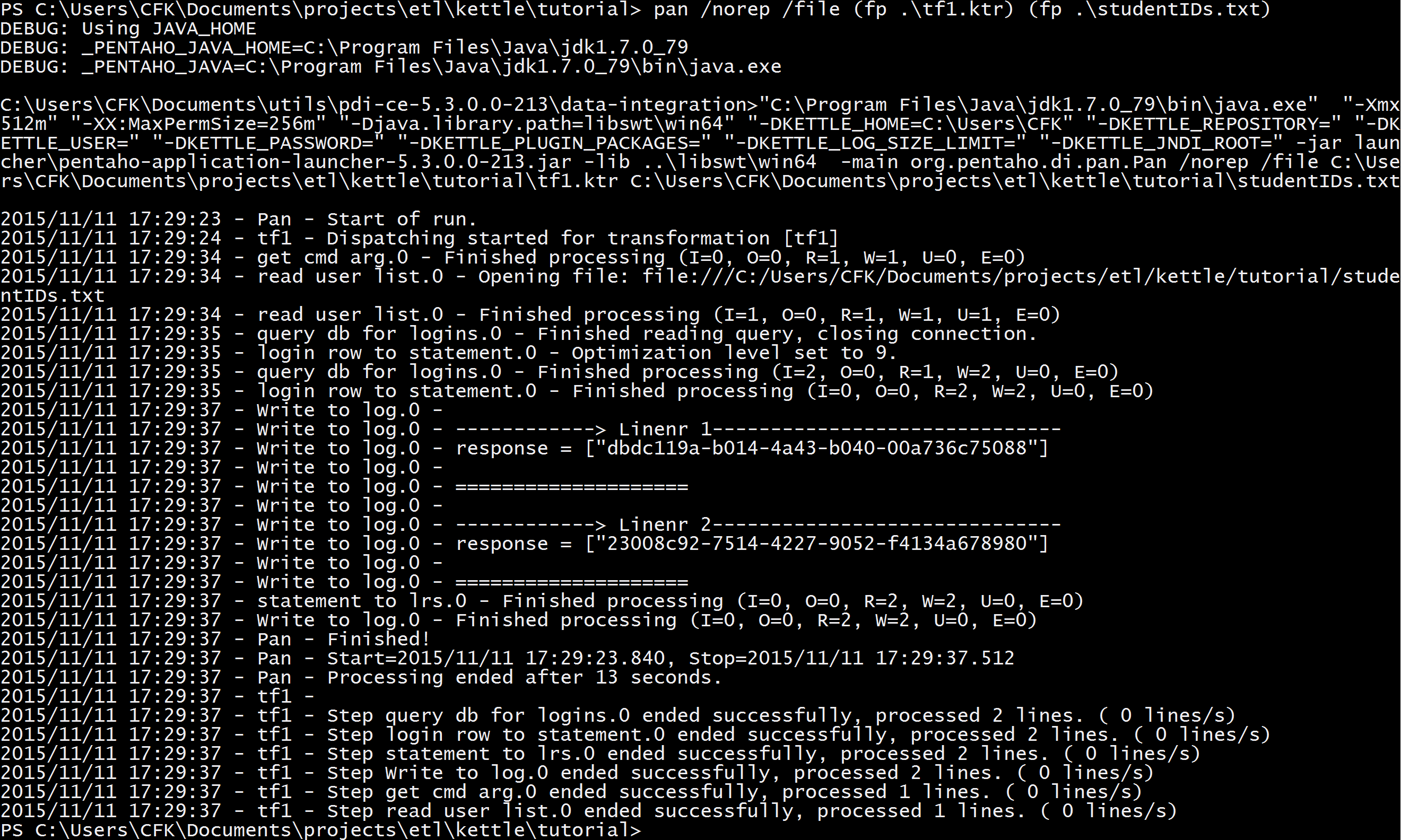
Hang on, though - if we schedule this transform to run regularly (say, once every day), it's going to send a lot of duplicate statements to the LRS (because there's no functionality to check what rows we've already seen, and indeed that's not possible to do in a single transform because - quite sensibly - identical rows generated by the same transform at different times will be parsed as logically different); because the LRS only cares about form and not about content, it'll accept them, analytics based on the LRS will go off the rails, and everyone will be pissed off. How do we make sure we're only sending statements we haven't already sent?
Pre-dinner mayonnaise Functional flavor
Conceptually, this isn't a particularly tricky requirement. We just need a timestamp after which we know for sure there aren't any of our statements in the LRS. However, there are several things that make this slightly less straightforward in practice:
- Obviously, we need to know the latest timestamp before we query the DB, because we have to add it as a filter on that query. However: Kettle transforms, by design, don't guarantee that rows will pass through in any given order, so whatever we do, we can't be getting the latest timestamp in same transform that uses it.
- Additionally, xAPI is an open standard, and it would be obstructively naïve to imagine that we're developing the only application that'll ever be storing statements in the LRS; as such, we don't just need the timestamp of the most recent statement in the LRS: we need the timestamp of the most recent statement that we know we sent.
- However, we can't actually ask the LRS itself what this timestamp is: the LRS runs on top of CouchDB, which is a document-based DB you interact with through a REST API. This means there are two ways to find a given document: either you include its ID directly in the HTTP query parameters, or you craft that query such that the document is included in the result set. The catch is that the set of documents you receive as a response to the latter query might not actually be identical with the set of all documents that match the query: before a document can be successfully queried for by anything other than its ID, CouchDB has to index it (generate a view that includes it).
- This means that if you pump a metric shit-ton of documents into the LRS at once, and then ask for the timestamp of the most recent one before all of them have been indexed, you're not going to get the timestamp you expect; you're going to get the timestamp of the statement which the LRS' DB has most recently indexed. If you then use this timestamp as a boundary condition for the next batch of statements, you're going to get some degree of overlap in the periods of time covered by two subsequent batches, which (especially if you're sending a lot of volume to begin with) can result in a lot of duplicate statements, which is exactly what we're trying to avoid.
- There are a variety of ways to solve this; what seems like the safest thing is to check beforehand if indexing is complete, and don't send any new statements if it's not. (Blackboard data will continue to be there, so it's not like you're failing to record activity if you're not constantly sending statements.) Fortunately, xAPI specifies a property for this. According to the spec, the
storedproperty is the timestamp representing the point when the statement was "made available for retrieval"; since a statement logically has to be stored after it was received, all we need to do is record the timestamp of the latest POST request in every batch, and check to make sure thestoredproperty of the most recently-indexed statement is later than that. (It's also possible to query CouchDB itself for a list of active tasks, including indexing, but that would generally either require us to be running our transforms on the same machine as the LRS or have it configured for remote administration, both of which are neither guaranteed nor even necessarily good ideas in this context.) - Finally, it's important to note that the timestamp of the latest POST request (which we need to check whether or not to run at all) is not identical with the timestamp of the statement sent as the body of that request (which we need, in the event we decide to run, to limit the result set of the database queries).
Keeping order
In any case, the decision to run or not obviously has to be made before running the transformation we just wrote. As mentioned, Kettle transforms don't have a fixed step order (the arrows just define where a row can go from any given step); Kettle jobs, though, most certainly do.
A job is one step up the scope/abstraction ladder; the main feature of a job is that you can run transforms from within it, and they're guaranteed to run in the order you specify, so there's an amount of certitude about the output of a particular job step (unhelpfully called a job entry in the docs even though they're isomorphic to transform steps) that you don't get in a transform.
So, the first thing to do is to write a transform that'll check whether or not it's safe to run, and after that we'll incorporate both transforms in a job (meaning we'll also have to modify the first transform to additionally record the data we need to make the above determination).
Checking indexing
Start with a new transform and a blank workspace; this time, though, I'll assume increasing facility with Kettle (and its barely-there docs), so that we can do some of the thinking ahead of time and in a nutshell with regard to which steps we'll need and why:
- We know we need two timestamps before we start running: the latest POST request made by the last-run instance of our main transform, and the latest activity recorded in a statement by that transform. There are probably more ways to do this than there are developers who could implement it, so let's pick a simple solution and stick with it: the main transform will append each of those to its own text file, so that the job can read the last lines of both as separate command-line arguments. This means our new transform will need the Get System Info step to parse one of those arguments.
- We'll need the REST Client step to query the LRS and the Json Input step to parse its response.
- To be able to compare the timestamp of the latest POST with the most-recently-stored statement, we'll need to combine them into a single row, so we'll need Join Rows (cartesian product).
- Importantly, though, the Json Input step can specify a datatype for the fields it parses, but a command-line argument has to be a string, so we'll also need a Select values step to make the fields logically comparable.
- To actually perform the comparison, we need a Filter rows step; in Kettle-land, anything not an explicit failure is a success, so we need an Abort step at the very least (and let's also add a Write to log step for some visible confirmation that things are happening as we expect).
We're also going to need the Generate Rows step, since the REST Client step needs some input that we can't declare in its configuration. The workspace should look like this:
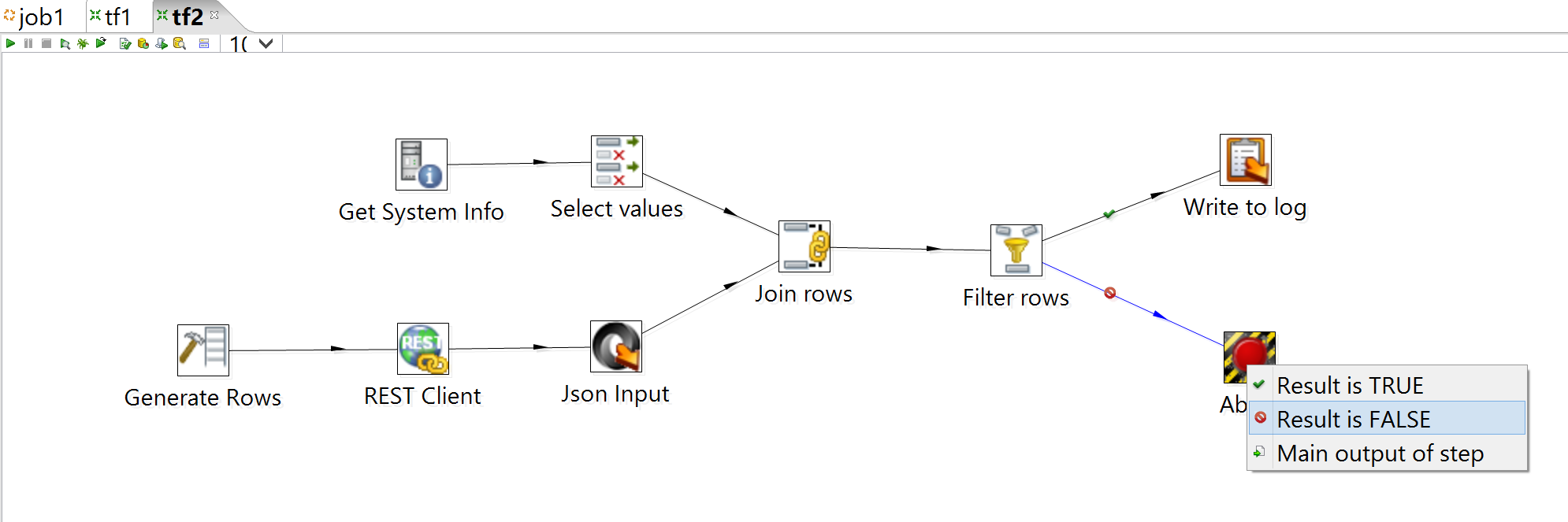
You'll notice that you have a choice of output types when you go to connect Filter rows and the steps following it. This is pretty straightforward.
Configuration of Generate Rows is also not complicated:
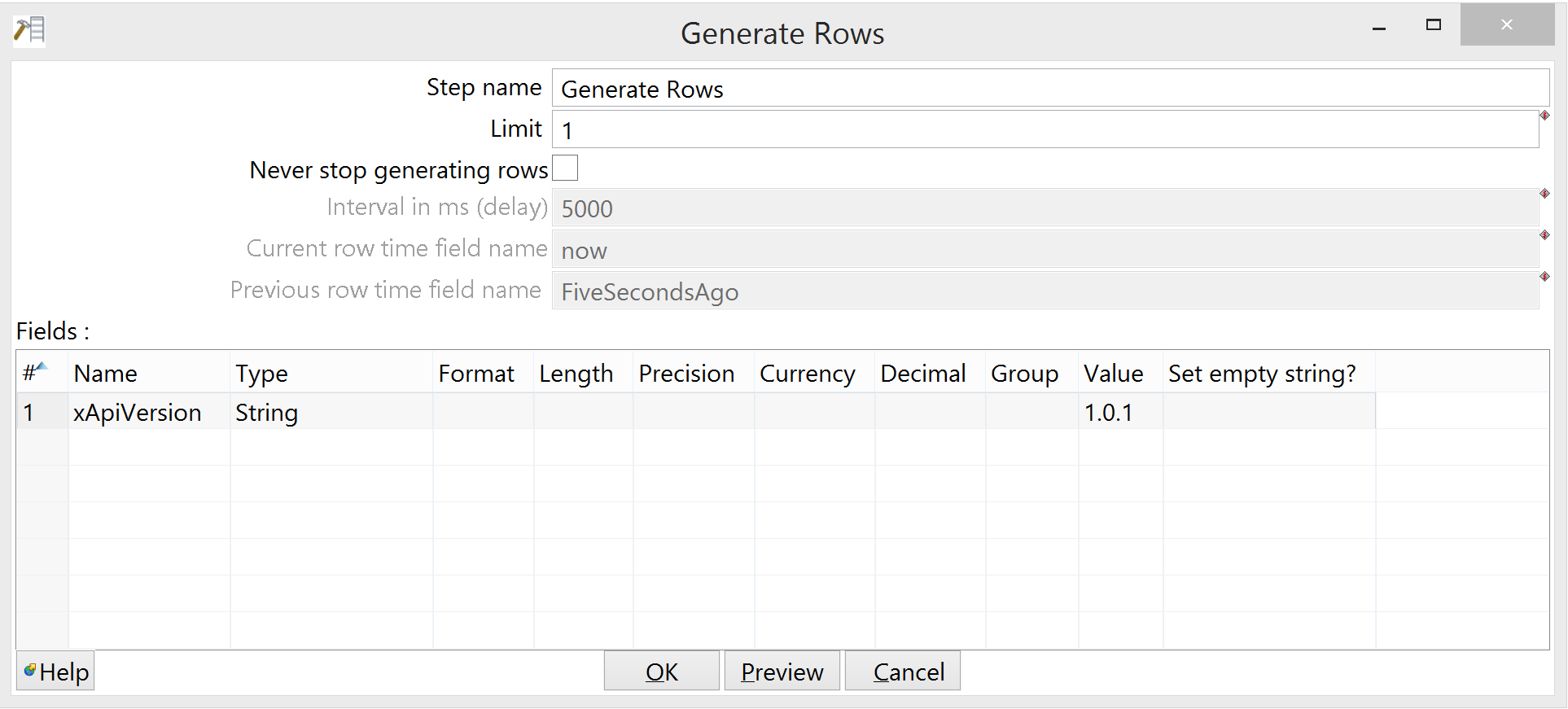
We're just setting the value of the X-Experience-API-Version header the way the REST Client step receives it from the row-to-statement step in the main transform, and sending it once.
The REST Client step needs a little more talking about, although the "Authentication" and "Headers" tabs should look identical to the ones in the main transform:
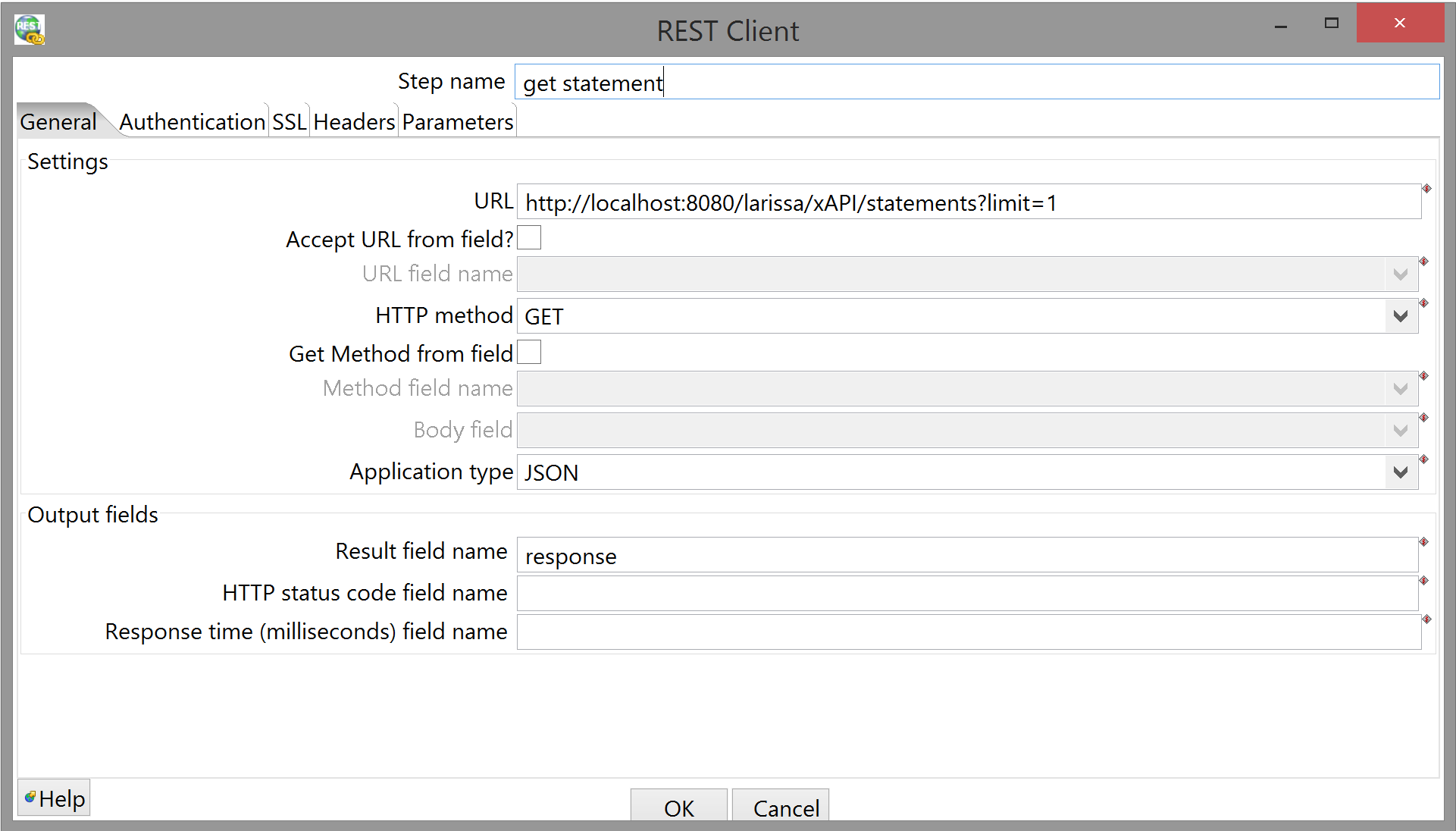
You can't declare headers in the step config, but at least you can specify the whole query: the URL to which we're POSTing in the main transform is also the one we GET from, but we also need to append a query string or we'll just get the 500 most recent statements (which is the order in which the LRS returns them by default, so we don't have to specify that) and a URL to GET from if we want the next 500. As you can see, we're just telling the LRS we want a single statement.
The options available when constructing a query are fully documented in the xAPI spec, in the section on the Statement API.
The "Content" tab of the Json Input step you can leave as-is; the "File" tab only requires that you specify the field with incoming JSON:
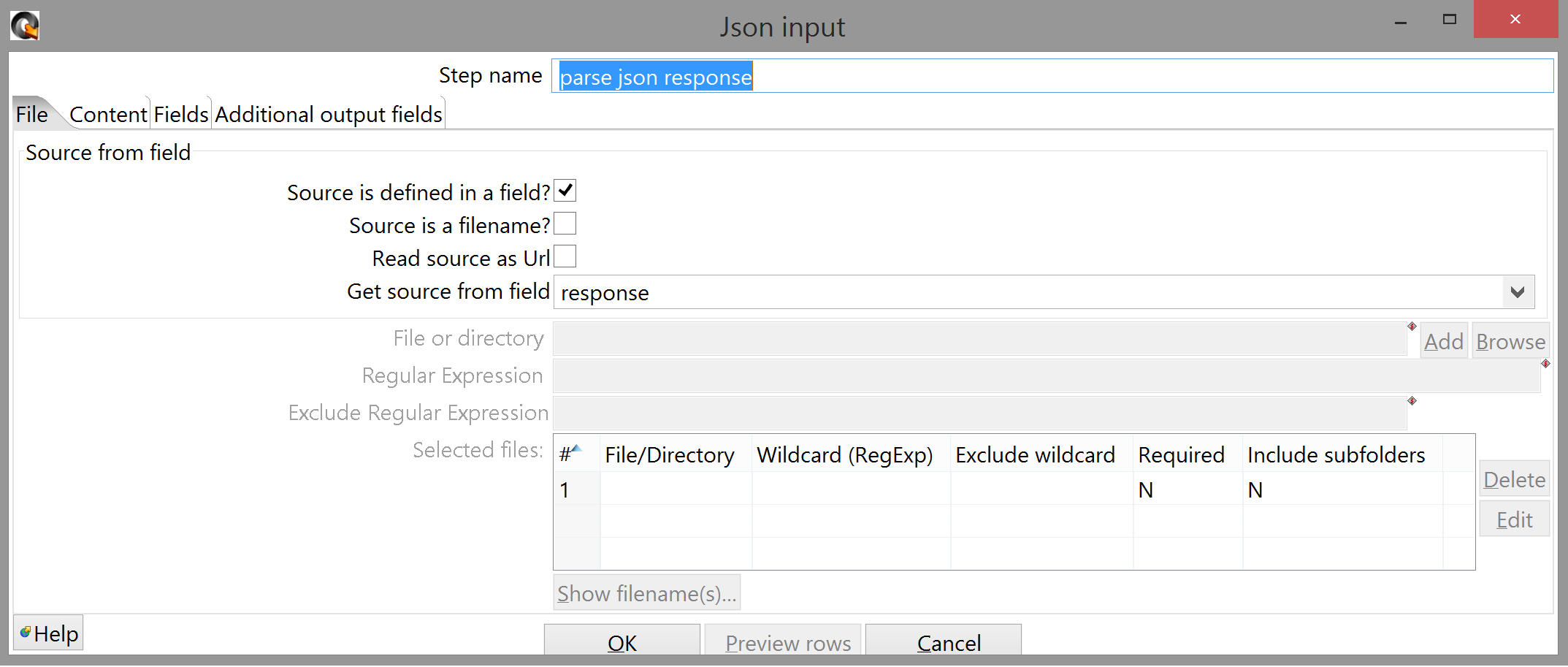
The "Fields" tab is almost entirely straightforward as well, except for the "Path" field; this uses JSONPath syntax to parse the JSON it receives.
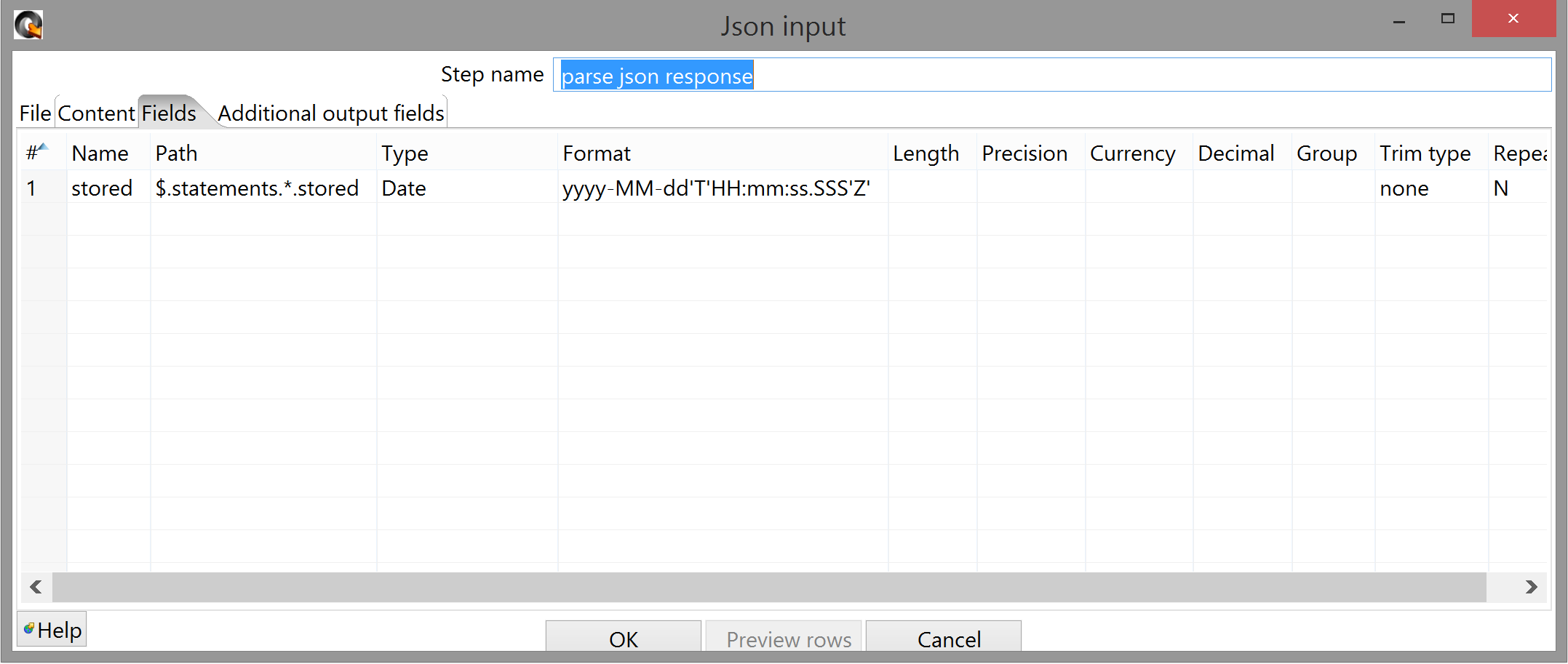
Here's a breakdown of the syntax we're using, in case it's not totally clear:
$ . statements
-----------------------------------------------------------------------
^ root node ^ one level down ^ name of property (here, an array)
.
-----------------------------------------------------------------------
^ down again (reaches some specific array element/s)
*
-----------------------------------------------------------------------
^ every element at the current depth (ie. all statement objects)
. stored
-----------------------------------------------------------------------
^ down again (reaches each statement) ^ name of property
The Get System Info step is about as simple as it gets; give the field a name, and select "command line argument 3" from the list that appears when you click the "Type" field. (I used the second argument for the statement timestamp because that makes sense to me: it's both causally and logically prior to the POST request that sends it. YMMV. The first argument, of course, is still the list of consenting student IDs.) The Select values step is only slightly less straightforward; it's worth noting that you apparently have to tell the step to select a field in the "Select & Alter" tab before you can change its type in the "Meta-data" tab. Also, make sure you use the correct date format anytime you're casting a string to a date or vice versa. (There's only one format being used in this entire tutorial, but that doesn't have to be the case.)
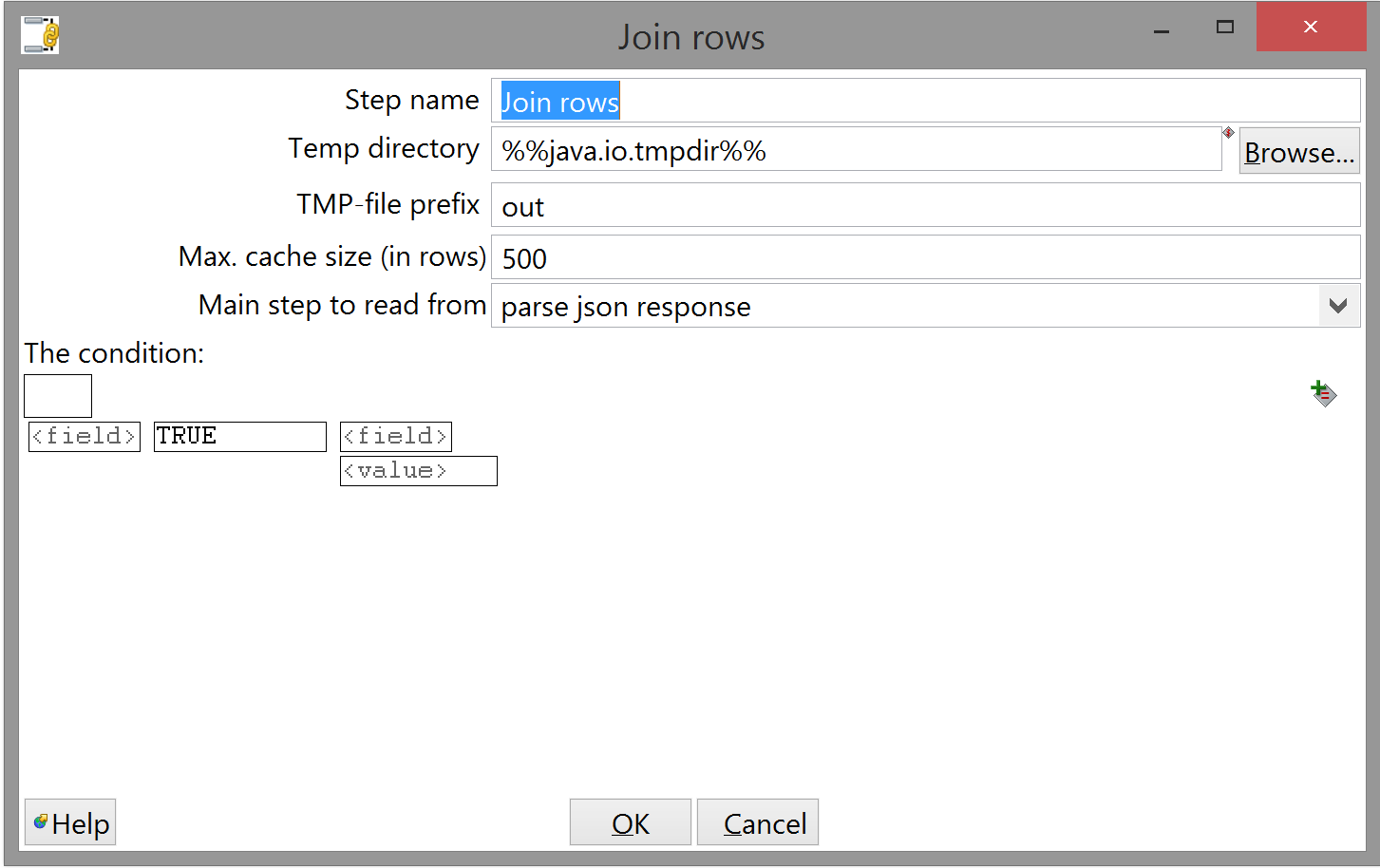
Join rows (cartesian product) is also fairly simple. We just want to make sure both dates are part of a single row, so we can set the condition to "TRUE"; a thing to pay attention to, however, is the "Main step to read data from" option. This will wait for rows from the specified input step by caching ones from any other input step. We know that the parsing and casting of the command-line argument will happen essentially instantaneously, while we might have to wait a second or two for a response from the LRS, so set this to parse json response:
Finally, make sure the filter condition is configured correctly: we want to continue if and only if the stored property on the statement we just received is later (ie. greater) than our last POST request.
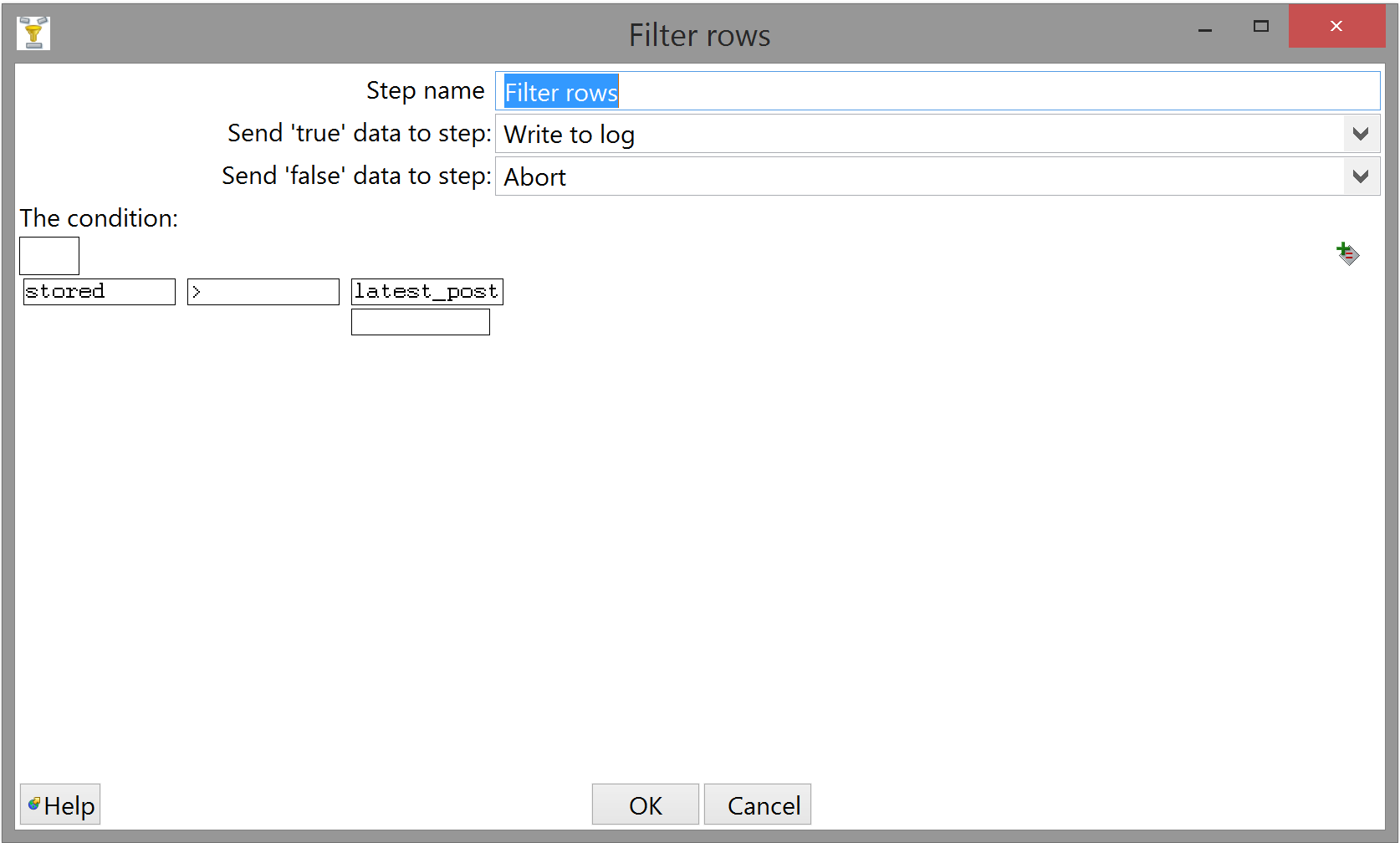
(Write to log and Abort should be self-explanatory by this point.)
Jobs well done
Ctrl+Shift+N creates a new job, and the workspace looks identical to that of a transform; the only real difference is that the sidebar gives you different steps (sorry, "entries"). All you really need to know is here:
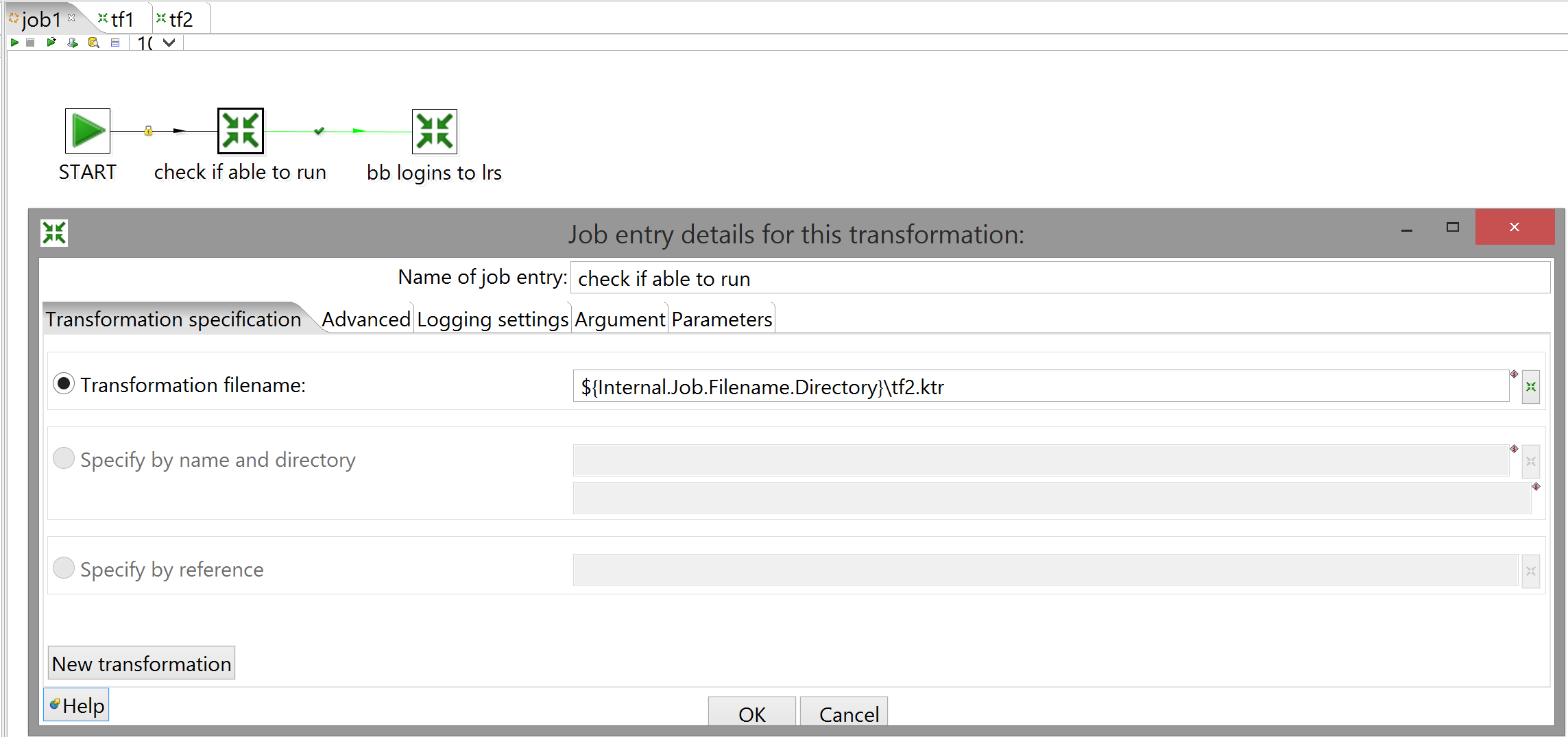
You only need the START and Transformation entries, and when configuring the latter, all you need to do is enter the path to the transform in question. That little <$> symbol next to some configuration fields (which you have undoubtedly seen elsewhere) means that the value of a variable can be used for all or part of that field; select the field and hit Ctrl+Space to see which ones are available. Kettle predefines a few for you; in this case, we want ${Internal.Job.Filename.Directory}, which does exactly what it says on the tin. (This means you'll have to keep the transforms in the same directory as the job; feel free to modify as you see fit, or even hardcode the paths, as long as the job knows exactly where to find the transforms.) One thing worth mentioning: you'll notice that the hop between the two transforms is green with a little check mark; this works similarly to the Filter rows step in that you can specify different output steps based on whether the result of a transform was success or failure. You can also click the symbol to cycle the hop between states: success, failure and a little lock symbol that means the next transform is run unconditionally.
Now that that's sorted, we have to modify the main transform, to accept an additional argument as a filter on the query, and to append both of the timestamps we need to separate text files.
Finishing touches
There are a number of small-but-significant things to be done here, some of which may not be immediately obvious:
- configure get cmd arg to also read the second command-line argument;
- configure read user list to "Pass through fields from previous step";
-
add a line to query db for logins, casting the new field to an appropriate datatype and filtering on it:
-- ... and u.user_id = ? and aa.timestamp > to_date(?,'YYYY-MM-DD"T"HH24:MI:SS".000Z"')
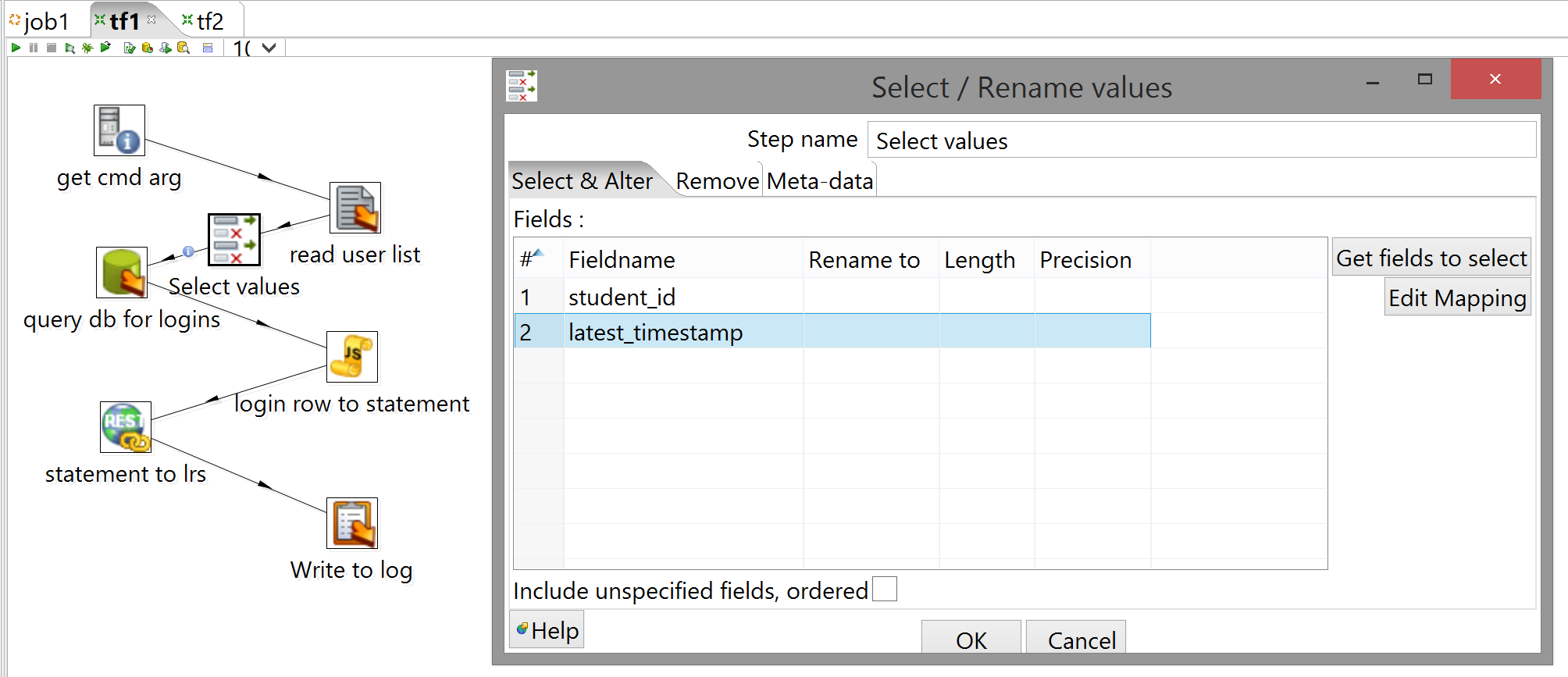
-
because you're now getting a superfluous field from read user list (the filename of the user list in question), add a Select values in between read user list and query db for logins, to filter that out (and make sure the fields you do want are being passed through in the correct order, since that matters for the query's purposes). You can drag the step directly onto the hop and Kettle will ask you if you want to interpose it:
So that's the filter taken care of; however, while we can run the job by manually entering correctly-formatted datetime strings, it's not quite ready for deployment. Here's where it gets slightly more tricky (but only slightly):
-
Add another Select values step, after the query step but as a separate output (as opposed to interposing it between that step and login row to statement), to filter out everything but the timestamp, and cast it back to a "Date" datatype (pay attention to the format mask, as this is once again Java string parsing and not case-smashing SQL). If you haven't configured the appropriate option when you try to create a hop from a step that already has an output step, Kettle will ask you to pick "Distribute" or "Copy" as the behavior of the step you're linking from with regard to the rows that leave it; we want "Copy", which is also the default once you tell Kettle to stop asking.
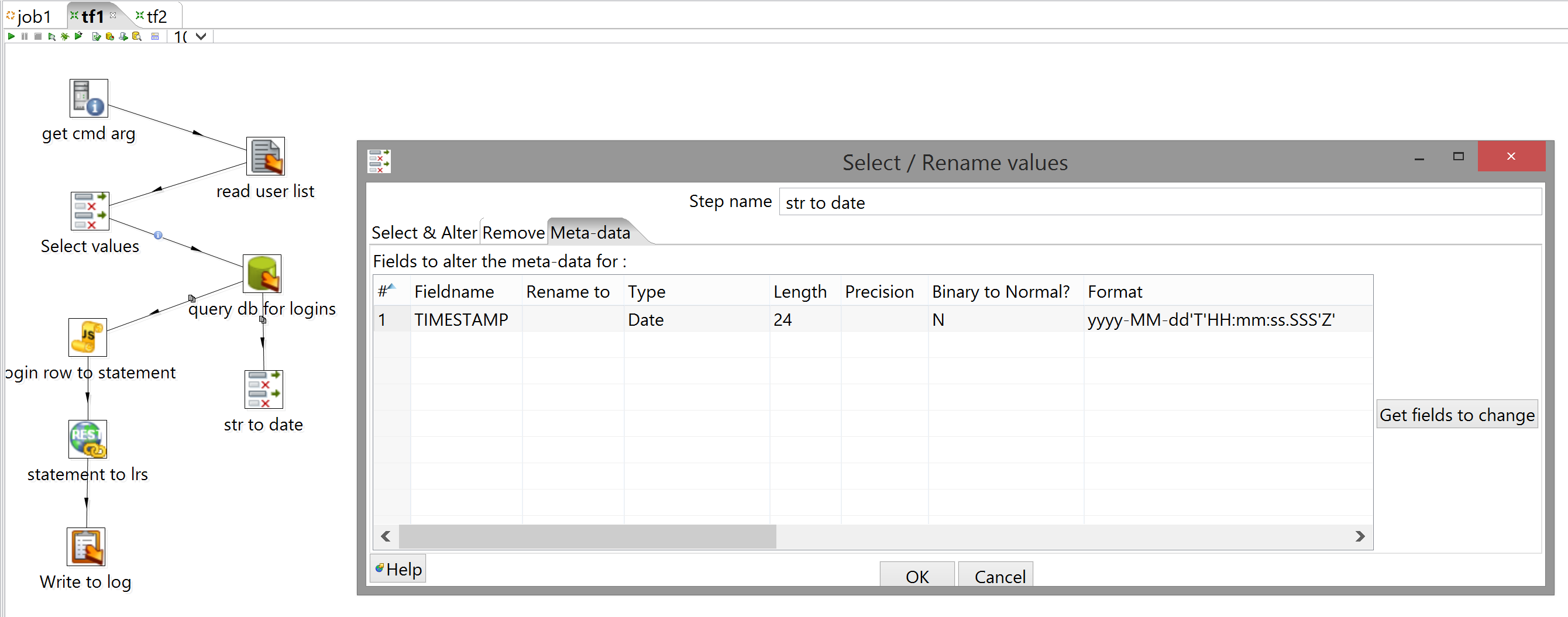
-
Add a Memory Group by step after that. This step is an aggregator, caching the fields you tell it to from all the rows it receives and performing some transformation on the whole group. The upper table contains fields that are passed through as-is, and the lower table contains fields on which some aggregation is done. These are exhaustive: similarly to Select values, if a field doesn't appear in either table, it doesn't appear in the output.
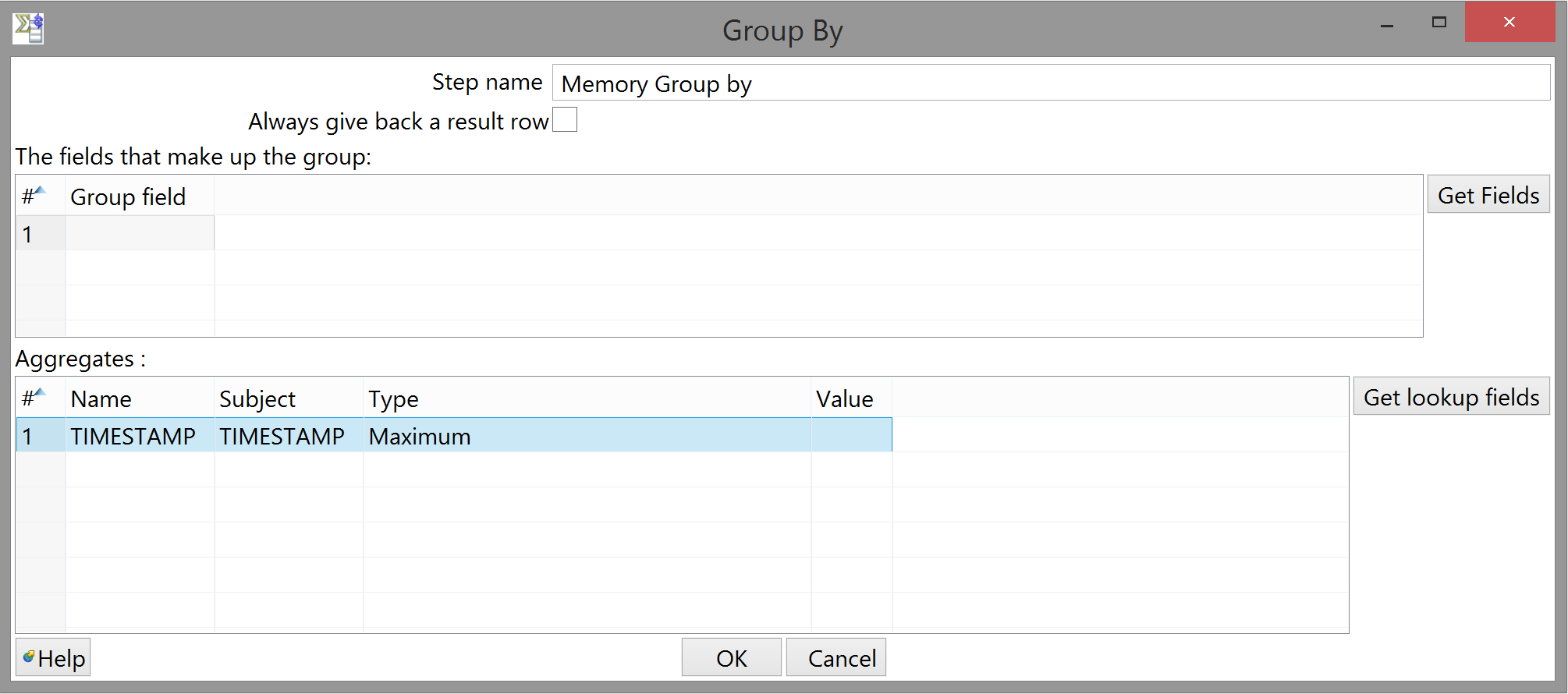
Add yet another Select values; if you didn't, Kettle would write the timestamp to disk in whichever format it damn well pleased, and since the query expects a string of a particular format, we want a little more control over the output than that. (You could also modify the query to expect whatever format Kettle uses by default, but I like my solution better. YMMV.)
- Finally, add a Text file output step, append the string representing the latest timestamp to a file in the same directory as the parent job (you have to explicitly tell it to append rather than clobber, but it'll quietly create the file if it doesn't exist yet). Remember that Kettle thinks this is basically a CSV file, so make sure you also tell it not to use enclosures or a header.
That's one timestamp; the other is essentially the same deal. You'll need another Get System Info, Memory Group by, Select values and Text file output; helpfully, when Get System Info isn't used purely as an input step, it appends its fields to rows passed through it, so you just have to copy the output of the REST call (ie. the response confirming the LRS has received a statement) to that step and select "system date (variable)" as the type of the new field. (You don't have to interpose a Select values between Get System Info and Memory Group by because the system date is already a sensible datatype.) When you're through, the workspace should look something like this:
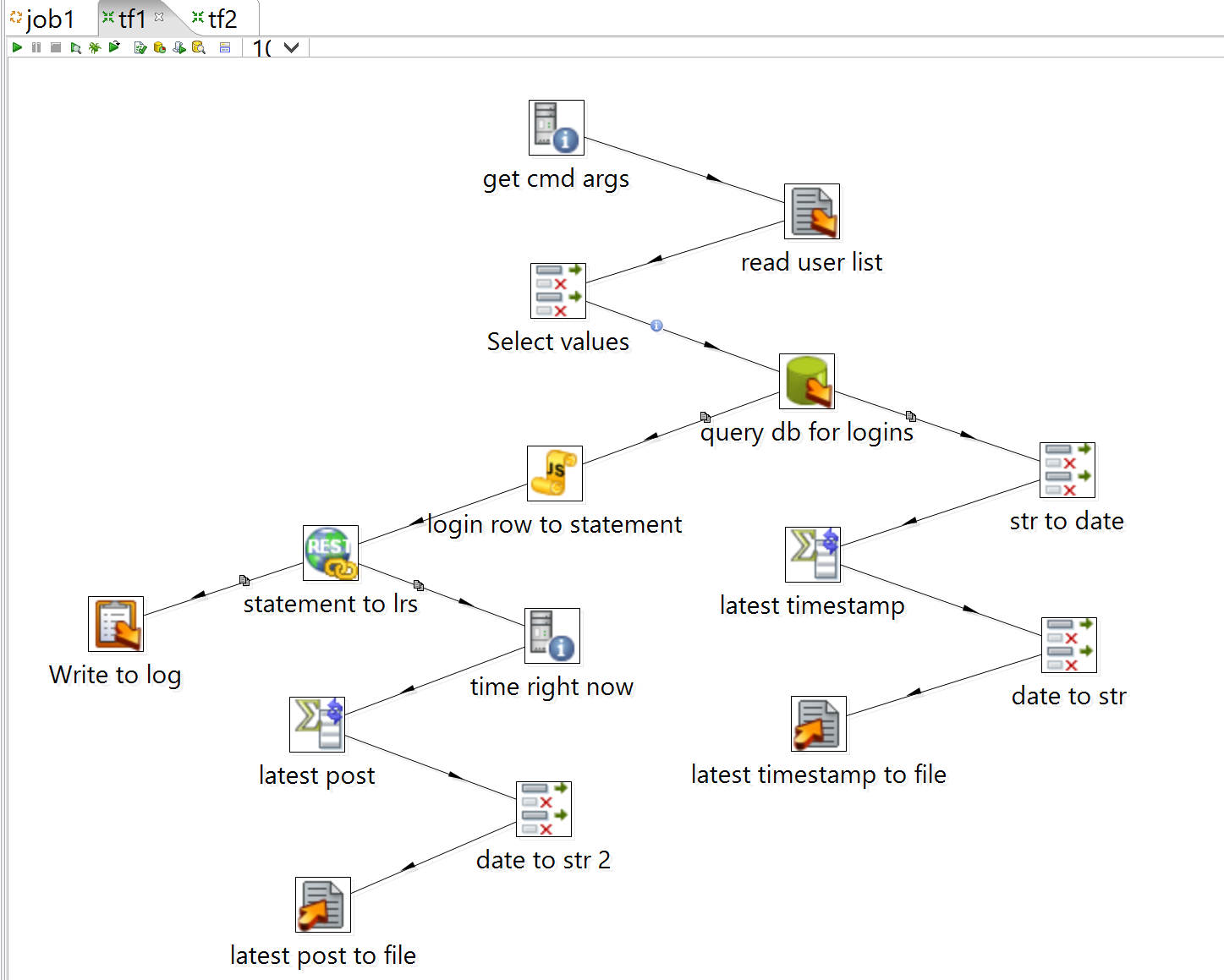
(Re)Deploying
Fortunately, Kettle is tool-agnostic when it comes to parsing command-line arguments; this means all you really have to do with the invocation is change pan to kitchen, and the name of the transform to the name of the overarching job.
$ sh ~/data-integration/kitchen.sh -norep -file /full/path/to/job1.kjb \
/full/path/to/studentIDs.txt
> kitchen /norep /file (fp .\job1.kjb) (fp .\studentIDs.txt)
However. Here's the part where I get less than totally system-agnostic, as a matter of principle: the way I prefer to pass the appropriate timestamps to the job is like this:
$ sh ~/data-integration/kitchen.sh -norep -file /full/path/to/job1.kjb \
/full/path/to/studentIDs.txt \
`tail -1 /path/to/latest_timestamps.txt` \
`tail -1 /path/to/latest_posts.txt`
You can do command substitution in essentially the same way on Windows (and in fact I'm using it to get the full paths of things), but there really should be something equivalent to tail. Someone has ported the GNU coreutils to Windows by now, or alternatively you could write a PowerShell script, but here we are either way.
And that's it! Drop the job, transforms, and list of consenting users on an arbitrary machine with an up-to-date JRE and Kettle installed (ie. downloaded, unpacked, environment variables set), and you can schedule it to run however often you like.
Additional resources
These are deliberately more rough-and-ready than the document you've just read.
Notes on what I already did at UvA